Crear un modelo de Machine Learning con Sklearn
Lectura y limpieza de datos
Para poner un modelo de Python en producción, primero debdemos crear un modelo. Y, para ello, lo primero es tener unos datos sobre los que realizar predicciones. Para ello, he utilizado este dataset, el cual incluye información del precio de las casas de Madrid.
De esta forma, el objetivo del proyecto es crear un modelo que, con 4 o 5 permita predecir el precio de una casa en Madrid. Así, cuando tengamos el modelo en producción, podremos crear un formulario con esos campos para que las personas estimen el precio de sus viviendas en Madrid, de una forma sencilla.
Nota: en este post no me voy a centrar en las opciones que ofrece Sklearn para crear modelos. Si quieres profundizar sobre Sklearn y todas las opciones que te ofrece, te recomiendo que te leas este post.
Así pues, lo primero de todo leemos los datos:
import pandas as pd
url = 'https://raw.githubusercontent.com/anderfernandez/datasets/main/Casas%20Madrid/houses_Madrid.csv'
data = pd.read_csv(url )
data.info()
RangeIndex: 21742 entries, 0 to 21741
Data columns (total 58 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Unnamed: 0 21742 non-null int64
1 id 21742 non-null int64
2 title 21742 non-null object
3 subtitle 21742 non-null object
4 sq_mt_built 21616 non-null float64
5 sq_mt_useful 8228 non-null float64
6 n_rooms 21742 non-null int64
7 n_bathrooms 21726 non-null float64
8 n_floors 1437 non-null float64
9 sq_mt_allotment 1432 non-null float64
10 latitude 0 non-null float64
11 longitude 0 non-null float64
12 raw_address 16277 non-null object
13 is_exact_address_hidden 21742 non-null bool
14 street_name 15837 non-null object
15 street_number 6300 non-null object
16 portal 0 non-null float64
17 floor 19135 non-null object
18 is_floor_under 20572 non-null object
19 door 0 non-null float64
20 neighborhood_id 21742 non-null object
21 operation 21742 non-null object
22 rent_price 21742 non-null int64
23 rent_price_by_area 0 non-null float64
24 is_rent_price_known 21742 non-null bool
25 buy_price 21742 non-null int64
26 buy_price_by_area 21742 non-null int64
27 is_buy_price_known 21742 non-null bool
28 house_type_id 21351 non-null object
29 is_renewal_needed 21742 non-null bool
30 is_new_development 20750 non-null object
31 built_year 10000 non-null float64
32 has_central_heating 13608 non-null object
33 has_individual_heating 13608 non-null object
34 are_pets_allowed 0 non-null float64
35 has_ac 11211 non-null object
36 has_fitted_wardrobes 13399 non-null object
37 has_lift 19356 non-null object
38 is_exterior 18699 non-null object
39 has_garden 1556 non-null object
40 has_pool 5171 non-null object
41 has_terrace 9548 non-null object
42 has_balcony 3321 non-null object
43 has_storage_room 7698 non-null object
44 is_furnished 0 non-null float64
45 is_kitchen_equipped 0 non-null float64
46 is_accessible 4074 non-null object
47 has_green_zones 4057 non-null object
48 energy_certificate 21742 non-null object
49 has_parking 21742 non-null bool
50 has_private_parking 0 non-null float64
51 has_public_parking 0 non-null float64
52 is_parking_included_in_price 7719 non-null object
53 parking_price 7719 non-null float64
54 is_orientation_north 11358 non-null object
55 is_orientation_west 11358 non-null object
56 is_orientation_south 11358 non-null object
57 is_orientation_east 11358 non-null object
dtypes: bool(5), float64(17), int64(6), object(30)
memory usage: 8.9+ MB
En estos casos puede que haya muchos valores de texto que únicamente tengan un valor. Por tanto, comprobamos si esto ocurre o no:
import numpy as np
str_cols = data.select_dtypes(['object']).columns
str_unique_vals = data[str_cols]\
.apply(lambda x: len(x.dropna().unique()))
str_unique_vals
title 10736
subtitle 146
raw_address 9666
street_name 6177
street_number 420
floor 19
is_floor_under 2
neighborhood_id 126
operation 1
house_type_id 4
is_new_development 2
has_central_heating 2
has_individual_heating 2
has_ac 1
has_fitted_wardrobes 1
has_lift 2
is_exterior 2
has_garden 1
has_pool 1
has_terrace 1
has_balcony 1
has_storage_room 1
is_accessible 1
has_green_zones 1
energy_certificate 10
is_parking_included_in_price 2
is_orientation_north 2
is_orientation_west 2
is_orientation_south 2
is_orientation_east 2
dtype: int64
Como veis, tenemos varios casos (has_green_zones, has_ac) donde solamente hay un único valor. Comprobamos un par de esos caso a ver qué pasa con esas columnas:
print(data['has_garden'].unique())
print(data['has_pool'].unique())
[nan True]
[nan True]
Si te fijas, en ambos casos está el valor True y el nan. Parece que en este caso el nan es, en realidad, un False. Lo cambio.
str_unique_vals_cols = str_unique_vals[str_unique_vals == 1].index.tolist()
data.loc[:,str_unique_vals_cols] = data\
.loc[:,str_unique_vals_cols].fillna(False)
Hecho esto, ahora sí vamos a seguir con la limpieza de datos. En este sentido, voy a hacer dos cosas:
- Eliminar variables con un alto porcentaje de valores perdidos.
- Eliminar variables que no me sirvan para la predicción, como el nombre de la calle o el precio del alquiler (si una persona no saber por cuánto vender su casa, seguramente tampoco sepa por cuánto alquilarla).
Nota: si quisiéramos crear el mejor modelo posible quizás no haríamos este segundo paso, puesto que podría darnos información relevante de la zona en la que se ubica la vivienda. Sin embargo, el objetivo no es crear el mejor modelo posible, sino aprender cómo puedes poner un modelo de Python en producción. La capacidad predictiva del modelo, en este caso, me importa poco.
# Elimino variables con mucho NA
ind_keep = data.isna().sum() < 0.3 * data.shape[0]
data = data.loc[:,ind_keep]
# Remove columns
data.drop([
'title', 'street_name','raw_address',
'is_exact_address_hidden','is_rent_price_known',
'is_buy_price_known', 'subtitle',
'floor','buy_price_by_area', 'rent_price', 'id', 'Unnamed: 0'
], axis = 1, inplace = True)
Asimismo, grafico las correlaciones de los datos numéricos para ver si me encuentro algo:
import matplotlib.pyplot as plt
import seaborn as sns
# Cambio el tamaño
from matplotlib.pyplot import figure
plt.rcParams['figure.figsize'] = [12, 8]
plt.rcParams['figure.dpi'] = 100
str_cols = data.select_dtypes('object').columns.tolist()
num_cols = data.select_dtypes(['int', 'float']).columns.tolist()
# Selecciono datos numéricos
cor_matrix = pd.concat([data[num_cols]], axis = 1).corr()
sns.heatmap(cor_matrix)
plt.show()

Como vemos, de todas las variables numéricas las más correlacionadas con el precio de la vivienda son: el número de metros cuadrados construidos (sq_mt_built), el número de baños (n_bathrooms) y el número de habitaciones (n_rooms).
Como el objetivo es tener pocas variables predictoras (4 o 5) de momento me quedo con estas tres variables numéricas.
Ahora veamos cómo se comportan las variables categóricas:
import math
str_cols = data.select_dtypes('object').columns
fig, ax = plt.subplots( math.ceil(len(str_cols)/3), 3, figsize=(15, 15))
for var, subplot in zip(str_cols, ax.flatten()):
sns.boxplot(x=var, y='buy_price', data=data, ax=subplot)
plt.show()
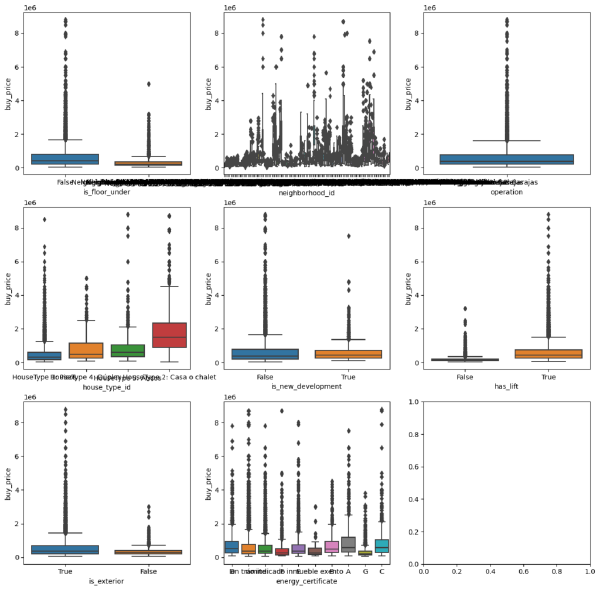
Como vemos, hay varios problemas en el dataset. Sin embargo, ahora mismo a nosotros no nos interesa eso. En su lugar nos interesa ver qué variables son las que más nos pueden ayudar de cara a la predicción del precio de una vivienda.
Visualmente, podemos ver como el tipo de vivienda (house_type_id) tiene unas diferencias bastante marcadas, al igual que el hecho de que tenga o no ascendor (has_lift). Aunque habría formas mejores de comprobarlo, para este ejemplo nos sirve con esto.
Así pues, vamos a usar estas 5 variables de cara a hacer la predicción del precio de la casa. Vamos a ello.
Creación del Modelo de predicción del precio de la vivienda
Lo primero para realizar el modelo será hacer el split entre train y test. Para ello usaré sklearn.
Nota: Si no conoces en profundidad Sklearn o hay funciones que uso que no conoces, te recomendaría que leyeras mi tutorial de Sklearn donde lo explico en profundidad.
Así pues, sigamos creando el modelo en Python para poder ponerlo en producción.
from sklearn.model_selection import train_test_split
keep_cols = ['sq_mt_built', 'n_bathrooms', 'n_rooms' , 'has_lift', 'house_type_id']
# Split de los datos
y = data['buy_price']
x = data[keep_cols]
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state = 1234)
print(x_train.shape, y_train.shape)
(16306, 5) (16306,)
Ahora que tenemos los datos cargados,voy a analizar la completitud de los datos y los outliers.
x_train.isna().sum()
sq_mt_built 98
n_bathrooms 10
n_rooms 0
has_lift 1828
house_type_id 286
dtype: int64
Como vemos, la has_lift tiene muchos valores perdidos. Puede que esto solo se de para un tipo de casa concreto. Lo analizamos:
x_train\
.assign(
n_nas = x_train['has_lift'].isnull(),
n_rows = 1
)\
.groupby('house_type_id')\
.sum()\
.reset_index()\
.loc[:,['house_type_id', 'n_nas', 'n_rows']]
house_type_id n_nas n_rows
0 HouseType 1: Pisos 312 13260
1 HouseType 2: Casa o chalet 1496 1496
2 HouseType 4: Dúplex 7 502
3 HouseType 5: Áticos 5 762
Como podemos ver, el 100% de los Chalets tienen el campo de ascensor vacío, ientras que en el resto de tipos de edificio apenas hay campos nulos.
En un chalet no suele haber ascensores, por tanto, fijaremos estos valores perdidos como False.
# Transformo en train y test
x_train.loc[
x_train['house_type_id'] == 'HouseType 2: Casa o chalet', 'has_lift'
] = False
x_test.loc[
x_test['house_type_id'] == 'HouseType 2: Casa o chalet', 'has_lift'
] = False
Si volvemos a comprobar los datos veremos como tenemos muy pocos valores perdidos:
x_train.isna().sum()
sq_mt_built 98
n_bathrooms 10
n_rooms 0
has_lift 332
house_type_id 286
dtype: int64
En cualquier caso, primero tendré que imputar el NA para poder hacer las predicciones. Para ello simplemente imputaré la moda (quizás no sea la mejor estrategia, pero como he dicho, el objetivo no es conseguir la mejor predicción posible).
De cara a hacer las predicciones no necesitaré guardar el diccionario modes que he creado, puesto que el propio formulario hará la validación de los datos y, por tanto, no habrá valores perdidos.
# Imputo NAs con la moda
import pickle
# Calculo las modas
modes = dict(zip(x_train.columns, x_train.mode().loc[0,:].tolist()))
# Imputo la moda
for column in x_train.columns:
x_train.loc[x_train[column].isna(),column] = modes.get(column)
Ahora que ya tengo los datos imputados podemos crear el modelo. Para ello, primer usaré Random Forest, puesto que suele dar buenos resultados.
from sklearn.metrics import mean_absolute_error
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import LabelBinarizer
# Defino el encoder
encoder = LabelBinarizer()
encoder_fit = encoder.fit(x_train['house_type_id'])
encoded_data_train = pd.DataFrame(
encoder_fit.transform(x_train['house_type_id']),
columns = encoder_fit.classes_.tolist()
)
# Add encoded variables
x_train_transf = pd.concat(
[x_train.reset_index(), encoded_data_train],
axis = 1
)\
.drop(['index', 'house_type_id'], axis = 1)
# Create model
rf_reg = RandomForestRegressor()
rf_reg_fit = rf_reg\
.fit(x_train_transf, y_train)
preds = rf_reg_fit.predict(x_train_transf)
mean_absolute_error(y_train, preds)
48713.740368575985
Como vemos, tenemos un error de 49.000€ en train. Veamos de cuánto es el error en test:
# Imputo la moda
for column in x_test.columns:
x_test.loc[x_test[column].isna(),column] = modes.get(column)
# One hot encoding
encoded_data_test = pd.DataFrame(
encoder_fit.transform(x_test['house_type_id']),
columns = encoder_fit.classes_.tolist()
)
x_test_transf = pd.concat(
[x_test.reset_index(), encoded_data_test],
axis = 1
)\
.drop(['index','house_type_id'], axis = 1)
preds = rf_reg_fit.predict(x_test_transf)
mean_absolute_error(y_test, preds)
131327.28633922
Como vemos, en test las diferencias son bastante más considerables. Si quisiéramos crear una herramienta útil, tendríamos que seguir mejorando el modelo. Sin embargo, en nuestro caso nos sive como prueba porque, como he dicho, el objetivo no es conseguir un buen modelo, sino enseñar cómo poner un modelo de Python en producción.
En definitiva ya tenemos el modelo. Pero ahora, ¿cómo lo ponemos en producción? Lo primero de todo es crear una API usando FastAPI.
Crear una API que haga predicciones con FastAPI
Para poner nuestra aplicación en producción, simplemente tendremos que crear una API usando FastAPI que reciba como parámetros los inputs del modelo y devuelva una predicción.
Nota: si no conoces cómo funciona FastAPI u otras herramientas para crear APIs en Python, te recomiendo que te leas este post donde lo explico.
Así pues, antes de crear la API, primero tenemos que guardar todos los objetos necesarios. Más concretamente: el OneHotEncoder y el modelo (el objeto modas no hace falta, puesto que no hará falta imputar valores perdidos, la lógica vendré en el formulario).
with open('app/encoder.pickle', 'wb') as handle:
pickle.dump(encoder, handle, protocol=pickle.HIGHEST_PROTOCOL)
with open('app/model.pickle', 'wb') as handle:
pickle.dump(model, handle, protocol=pickle.HIGHEST_PROTOCOL)
Ahora que ya tenemos los ficheros guardados, simplemente tenemos que crear una API con FastAPI en un fichero llamad main.py. Este fichero será como el siguiente:
from fastapi import FastAPI
app = FastAPI()
@app.post("/make_preds")
def make_preds(sq_mt:int, n_bathrooms:int,
n_rooms:int, has_lift:str, house_type:str):
import pickle
import pandas as pd
# Load Files
encoder_fit = pd.read_pickle("app/encoder.pickle")
rf_reg_fit = pd.read_pickle("app/model.pickle")
# Create df
x_pred = pd.DataFrame(
[[sq_mt, n_bathrooms, n_rooms, bool(has_lift), house_type]],
columns = ['sq_mt_built', 'n_bathrooms', 'n_rooms',
'has_lift', 'house_type_id']
)
# One hot encoding
encoded_data_pred = pd.DataFrame(
encoder_fit.transform(x_pred['house_type_id']),
columns = encoder_fit.classes_.tolist()
)
# Build final df
x_pred_transf = pd.concat(
[x_pred.reset_index(), encoded_data_pred],
axis = 1
)\
.drop(['house_type_id', 'index'], axis = 1)
preds = rf_reg_fit.predict(x_pred_transf)
return round(preds[0])
Ahora, podemos lanzar nuestra API y probar que funciona. Para ello, tendremos que tener el módulo uvicorn instalado y tendremos que ejecutar el siguiente código:
uvicorn main:app --reload
Por último, podemos comprobar que nuestra API devuelve el valor de la predicción. Para ello, vamos a realizar una petición POST a la misma (mientras esta se ejecuta en local):
import requests
sq_met = 100
n_bathrooms = 2
n_rooms = 2
has_lift = True
house_type = 'HouseType 1: Pisos'
url = f'http://127.0.0.1:8000/make_preds?sq_mt={sq_met}&n_bathrooms={n_bathrooms}&n_rooms={n_rooms}&has_lift={has_lift}&house_type={house_type}'
url = url.replace(' ', '20')
resp = requests.post(url)
resp.content
b'488557'
Como vemos, hemos podido ejecutar nuestro modelo dentro de la API y funciona correctamente.
Nota: a la hora de hacer la predicción suele ser buena idea comprobar los tipos de datos que entran y hacer un insert en alguna tabla para ir guardando los datos predichos. En nuestro caso, al tratarse de un formulario la validación de tipo de dato como el insert lo haría el propio formulario.
Así pues, ya hemos creado una API que nos permita ejecutar nuestro modelo. Ahora veamos cómo podemos poner nuestra modelo de Python en producción.
Cómo poner un modelo de Python en producción
Crear un Docker con el modelo
Aunque hay muchas formas de poner un modelo en producción, la más común suele ser crear un Docker. Si no lo conoces, Docker es un software que te permite crear entornos asilados, autoejecutables y portables, para que puedas ejecutar tu código en cualquier plataforma con Docker abstrayéndote de sistemas operativos, versiones de lenguajes y paquetes, etc.
Nota: en este post doy por supuesta cierta base de Docker. Sin embargo, si no sabes sobre Docker puedes aprender sobre ello en este post.
Así pues, lo primero de todo vamos a crear un Dockerfile que nos permita instalar todo lo necesario para ejecutar nuestra API. Para ello, hay que tener en cuenta que la carpeta donde tengo la app tiene los siguientes ficheros:
│ Dockerfile
│
│ requirements.txt
│
└───app
encoder.pickle
main.py
model.pickle
modes.pickle
Teniendo en cuenta que la carpeta es así, mi Dockerfile es el siguiente:
FROM tiangolo/uvicorn-gunicorn-fastapi
COPY requirements.txt .
RUN pip install -r requirements.txt
RUN mkdir -p app
COPY ./app app
EXPOSE 8080
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8080"]
Por último tenemos que montar la imagen, lo cual podemos hacerlo con la siguiente función:
docker build -t modelo_produccion_python .
Ahora que tenemos la imagen Docker montada, tenemos que subirlo a nuestra herramienta Cloud favorita. En mi caso, pondré el modelo de Python en producción en Google Cloud usando Cloud Run.
Subir modelo a un entorno Cloud
Ahora que tenemos nuestro modelo en un Docker, podemos subirlo a nuestro servicio Cloud favorito. En mi caso lo subiré a Cloud Run, de tal forma que el modelo escale de 0 (no pagar cuando no se esté usando) a lo que haga falta.
Así pues, usaré el Google Cloud SDK para subir la imagen Docker al Container Registry y así después hacer el deploy a Cloud Run.
Nota: de cara a la explicación, supongo que tienes una cuenta de Google Cloud creada y una cuenta de facturación asignada. Si no lo tienes, puedes aprender cómo hacerlo aquí.
Para ello, tenemos que:
- Instalar el Google Cloud SDK, el cual lo puedes instalar desde este enlace.
- Vincular tu ordenador con tu cuenta de Google Cloud. Para ello, simplemente debes ejecutar el siguiente comando:
gcloud auth login
- Vincular Docker con Google Cloud, de tal forma que puedas subir una imagen de tu Docker al Container Registry. Para ello simplemente debes ejecutar el siguiente comando:
gcloud auth configure-docker
- Etiquetar tu imagen para que pueda ser subida. Para poder etiquetar la imagen necesitas conocer es nombre de la imagen y el projectid. En mi caso, el nombre de la imagen es
modelo_produccion_pythony el id del proyecto esdirect-analog-185510. Así pues, tengo que ejecutar el siguiente comando:
docker tag modelo_produccion_python gcr.io/direct-analog-185510/modelo_produccion_python
# docker tag <image-name> grc.io/<project-id>/<image-name>
- Subir la imagen al Container Registry. Para ello, simplemente debes hacer un push de la imagen que acabas de crear. En mi caso:
docker push gcr.io/direct-analog-185510/modelo_produccion_python
Una vez tienes la imagen en el Container Registry, desde ahí podrás elegir en qué servicio quieres hacer el despliegue de la imagen, como se ve en la siguiente imagen:
Siguiendo los pasos, terminarás publicando tu imagen en Cloud Run.
Importante: si publicas la imagen en Cloud Run es importante que gestiones si las peticiones deben ser, o no, autentificadas. Si indicas que deben serlo, debes tener esto en cuenta de cara a hacer predicciones.
Por último, terminaremos teniendo una url. Podremos probar que nuestro algoritmo funciona haciendo peticiones a esta URL:
sq_met = 100
n_bathrooms = 2
n_rooms = 2
has_lift = True
house_type = 'HouseType 1: Pisos'
url = f'https://modelo-produccion-python-rk6gh2l6da-ew.a.run.app/make_preds?sq_mt={sq_met}&n_bathrooms={n_bathrooms}&n_rooms={n_rooms}&has_lift={has_lift}&house_type={house_type}'
url = url.replace(' ', '20')
resp = requests.post(url)
resp.content
b'488557'
Como ves, ya tenemos nuestro modelo en producción funcionando. Ahora simplemente tendríamos que enchufar para que nuestro formulario haga peticiones a este endpoint.
Conclusión
Como ves, crear modelos en Python es muy potente, pero saber poner un modelo de Python en producción es diferencial. Con este conocimiento no solo podrás poner tus propios modelos, sino que sabrás entender mejor a los DevOps (en caso de que en tu organización sean personas diferentes) o, incluso, crear aplicaciones basadas en machine learning en una forma mucho más sencilla.
Sin duda alguna esta es un ejemplo para un modelo sencillo. A partir de aquí todo se puede complicar mucho más: deployment continuo con Git y CI/CD, varios modelos en producción con varios endpoints, plataformas y tecnologías más complejas y escalables como Kubernetes, etc.
En cualquier caso, la idea básica generalmente siempre suele ser la misma: crear el modelo, crear una API para exponer el modelo, crear un Docker y ponerlo en producción.
Espero que este blog te haya servido. Si es así, te animo a que te suscribas a la newsletter para estar al día de nuevos posts. Y, como siempre, ¡nos vemos en el siguiente!