En este post aprenderás qué es Isolaiton Forest y cómo usarlo en Python, así como cuáles son sus principales ventajas e inconvenientes.
Y es que, uno de los principales problemas cuando trabajamos en la creación de modelos de Machine Learning son las anomalías. Detectar anomalías es complicado, más si trabajas con datasets muy extensos.
En este sentido, hoy aprenderemos sobre uno de los modelos de detección de anomalías más utilizados: Isolation Forest (o iForest). ¿Te suena interesante?¡Vamos con ello!
Qué y cómo funciona Isolation Forest
Isolation Forest es un método de detección de anomalías no supervisado, es decir, que se utiliza cuando no tenemos clasificadas las observaciones como anomalías o no (la gran mayoría de casos).
Para realizar esa detección, sigue una idea muy parecida a Random Forest: genera muchos árboles de decisión pequeños, llamados isolation trees.
Sin embargo, estos árboles no funcionan igual que un árbol de decisión normal ya que un Isolation Forest, en lugar de realizar las particiones más puras (medida mediante Gini o Entropía), realiza las particiones de forma aleatoria.
Concretamente, el proceso que sige Isolation Forest es el siguiente:
- Se realiza el encoding de las variables de texto: encoding ordinal en caso de variables ordinales y One Hot encoding en caso de las variables nominales.
- Selecciona una variable de forma aleatoria.
- Calcula una valor aleatorio dentro del rango de dicha variable (máximo o mínimo). Ese valor será el valor de partición para la variable.
- Se repiten los pasos 1 y 2 para cada uno de los splits.
Nota: si no conoces los conceptos de impureza o el funcionamiento de un árbol de decisión, te recomiendo que leas este post lo explico en detalle.
Con esto generaríamos un Isolation Tree o iTree. Isolation Forest consiste en crear muchos de estos de estos árboles. La idea detras de este procedimiento es que si una observación es muy diferente al resto, en pocas ramas se quedará aislado, mientras que el arbol será mucho más profundo.
Perfecto, ya sabemos cómo se crea un Isolation Forest, pero… ¿cómo decidimos si una observación es anómala o no? Veámoslo.
Anomaly score: cómo decidir si una observación es anómala
Para decidir si una observación es anómala o no, para cada observación se calcula su anomaly score. El anomaly score es una métrica que surge de la siguiente fórmula:
$$ s(x,n)=2−E(h(x))c(n) $$
En las que:
- h(x): es la profundidad (o altura) media de X de los iTrees construidos.
- c(n) es la altura media para encontrar un nodo en un Isolation Tree.
- n: es el tamaño del dataset.
En este sentido, si el valor de s es cercano a 1, seguramente se trate de una anomalía, mientras que, si el valor de s es inferior a 0.5, seguramente se trata de un valor no anómalo.
Perfecto, ya sabes qué es y Isolation Forest, ahora, veámos cómo usar Isolation Forest en Python. ¡Vamos con ello!
Cómo usar Isolation Forest en Python con Scikit-Learn
La forma más común de usar Isolation Forest en Python es con Scikit-Learn, así que vamos a ver cómo usar Isolation Forest en Python con Sklearn.
Si no conoces Scikit-Learn, te recomiendo que leas este post donde lo explico en detalle.
En este sentido, la implementación de Isolation Forest en Scikit-Learn cuenta con los siguientes parámetros:
- n_estimators: se refiere al número de árboles a crear.
- max_sample: se refeire al número de observaciones con las que se creará cada árbol. Este valor puede ser un entero o un float de 0 a 1, en cuyo caso representa el porcentaje de observaciones a utilizar.
- max_features: se refiere al número máximo de variables a incluir en cada árbol.
- contamination: este parámetro permite definirla proporción de valores atípicos del dataset. Si lo definimos como «auto», se usará la implementación original, mietras que si fijamos un
float, considerará ese porcentaje de valores como valores anómalos.
Perfecto, ahora que conocemos los parámetros principales, vamos a crear unos datos fake para ver qué tal se comporta este algoritmo. Para ello, primero debemos instalar la librería pyod, la cual es una librería clave para la detección de anomalías (enlace).
pip install pyod
Ahora que tenemos pyod instalado, vamos a cargar las librerías que vamos a utilizar a lo largo de esta sección:
import numpy as np
import math
import pandas as pd
import matplotlib.pyplot as plt
from pyod.utils.data import generate_data, get_outliers_inliers
import seaborn as sns
from sklearn.ensemble import IsolationForest
plt.rcParams["figure.figsize"] = (10,7)
np.random.seed(1234)
data, is_anomaly = generate_data(
n_features=2,
train_only=True,
random_state=1234
)
data = pd.DataFrame(data, columns = ['x', 'y'])
data['is_really_anomaly'] = is_anomaly
sns.scatterplot(
data = data,
x = 'x',
y = 'y',
hue = 'is_really_anomaly'
)
plt.title("Generated Random Data")
plt.show()
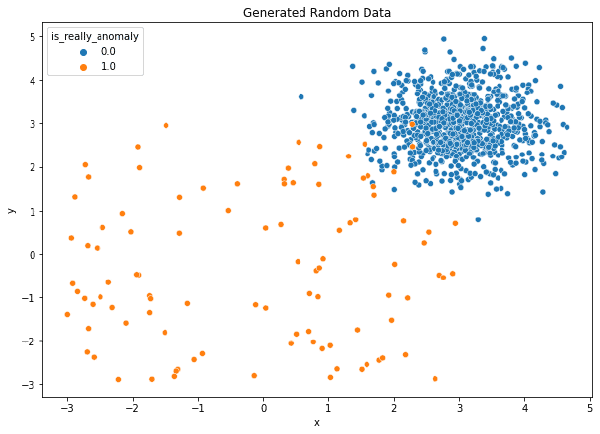
Como podemos ver hay algunos valores que son bastante diferentes al resto (una observación cuenta con un valor de x de 16, otra un valor de y de 9.6, etc.).
Como el resto de modelos de Sklearn, ajustamos Isolation Forest mediante el método fit y hacemos la predicción mediante predict. Veamos en cualquier caso cómo funciona:
iforest = IsolationForest(
n_estimators = 1000,
max_samples = "auto",
contamination= "auto"
)
iforest_fit = iforest.fit(data.drop('is_really_anomaly', axis = 1))
predictions = iforest_fit.predict(data.drop('is_really_anomaly', axis = 1))
data['is_anomaly_prediction'] = predictions
sns.scatterplot(
data = data,
x = 'x',
y = 'y',
hue = 'is_really_anomaly',
style="is_anomaly_prediction"
)
plt.title("Anomaly detection with Isolation Forest")
plt.show()
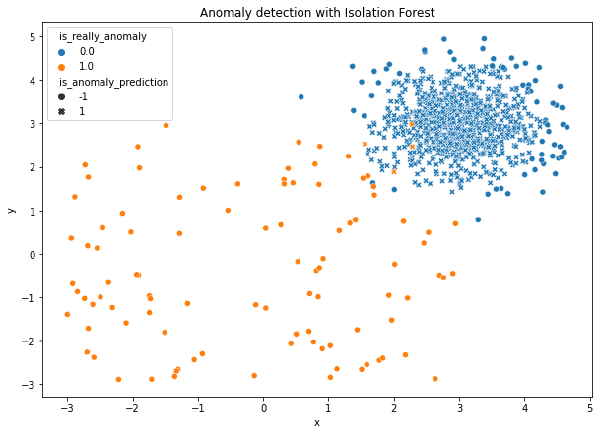
Como podemos ver, todas las observaciones centrales (que efectivamente no son anomalías) han sido consideradas como normales, mientras que las observaciones más externas han sido consideradas como anómalas.
En este sentido, Isolation Forest ha sido capaz de captar casi todas las anomalías, aunque ha sufrido ligeramente de masking, es decir, de considerar una observación no anómala como anómala.
A simple vista, parecería un resultado parecido al que podría arrojar otro modelo de detección de anomalías como DBSCAN.
Si quieres aprender sobre el algoritmo DBSCAN, puedes aprender más sobre él en este post.
Sin embargo, a diferencia de DBSCAN, con Isolation Forest podemos darle una paqueña vuelta, ya que podemos obtener el anomaly score y fijar nosotros un threshold (que es lo mismo que hace el parámetro contamination).
Para obtener el anomaly score debemos usar el método score_samples:
data['anomaly_score'] = -iforest_fit.score_samples(data[['x', 'y']])
sns.boxplot(
data = data,
x = 'is_really_anomaly',
y = 'anomaly_score'
)
plt.title("Anomaly score analysis")
plt.show()
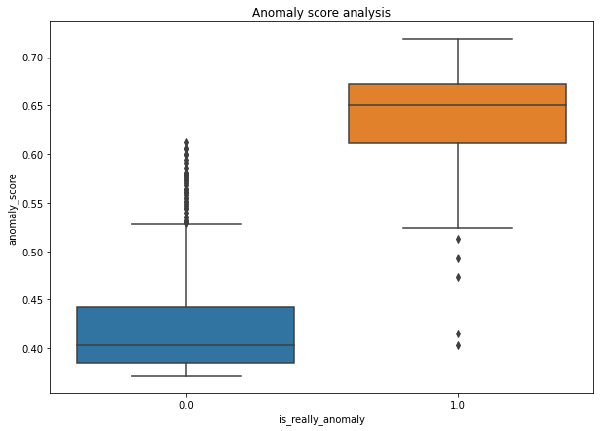
Como podemos ver, si ponemos el límite en 0.5, tal como se ha indicado previamente, vemos lo siguiente:
- Todas las observaciones anómalas salvo 4 tienen un anomaly score superior a 0.5, por lo que Isolation Forest parece captarlas correctamente. En otras palabras, el error de swamping.
- Existen varias observaciones no anómalas consideradas como tal, por lo que sí contamos con un problema de masking. En cualquier caso, estos casos son poco habituales, ya que están fuera de 1,5 veces el IQR del anomaly score de los casos no anómalos.
Ahora que tenemos un mayor conocimiento sobre cómo implementar un Isolation Forest en Python, veamos cómo afecta la alteración de los parámetros a los resultados del modelo. Para verlo más detalladamente, vayamos parámetro por parámetro.
Efecto de max_sample en Isolation Forest
Lo primero que podemos probar el efecto del tamaño de la muestra en la clasificación de los datos. Así pues, vamos a probar varios tamaños de muestra:
def make_prediction(kwargs):
iforest = IsolationForest(**kwargs)
iforest_fit = iforest.fit(data[['x', 'y']])
predictions = iforest_fit.predict(data[['x', 'y']])
return predictions
# Define the parameters
parameters = list(range(1, 99, 10))
parameters.append(100)
parameters = [{"max_samples": param/100} for param in parameters]
# Create the figures
plt.rcParams["figure.figsize"] = (20,10)
nrow = 3
fig, axes = plt.subplots(nrow, math.ceil(len(parameters)/nrow))
# Fill the figures
axes = axes.flatten()
for i, parameter in enumerate(parameters):
predictions = make_prediction(parameter)
data['is_anomaly_prediction'] = predictions
sns.scatterplot(
data = data,
x = 'x',
y = 'y',
hue = 'is_really_anomaly',
style="is_anomaly_prediction",
ax = axes[i]
)
axes[i].title.set_text(f"{str(parameter)}")
plt.tight_layout()
plt.show()
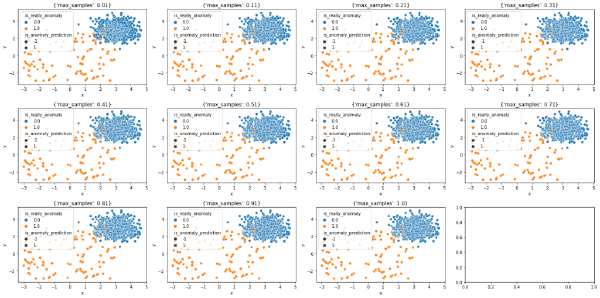
En este caso, parece que valores más pequeños de max_samples reduce el masking, es decir, el número de observaciones no anómalas consideradas como anómalas. Este efecto, aunque ligero, se puede apreciar en la parte inferior izquierda de los valores no anómalos.
Más adelante veremos el motivo de dichas diferencias y por qué es interesante aplicar un max_sampling bajo.
Asimismo, vamos a analizar el efecto de otro parámetro interesante: la contaminación.
Efecto de contamination en Isolation Forest
Respecto a la contaminación, es de esperar que, cuanto mayor sea el valor de contaminación, mayor será el número de observaciones clasificadas como anómalas.
En este sentido, es importante recalcar que el efecto de este parámetro dependerá mucho de cada caso:
- Un valor elevado de contamination en un dataset que se espera que tenga pocas observaciones anómalas reducirá el swamping, es decir, las observaciones no anómalas clasificadas como anómalas.
- Un valor bajo de contamination en un dataset que se espera que tenga muchas observaciones anómalas, supondrá un problema de masking, es decir, de considerar como no anómala una observación anómala.
Así pues, veamos este efecto en nuestro dataset anterior:
parameters = list(range(0, 30, 5))
parameters = [param/100 for param in parameters[1:]]
parameters.append("auto")
parameters = [{"contamination": param} for param in parameters]
plt.rcParams["figure.figsize"] = (20,10)
nrow = 2
fig, axes = plt.subplots(nrow, math.ceil(len(parameters)/nrow))
axes = axes.flatten()
for i, parameter in enumerate(parameters):
predictions = make_prediction(parameter)
data['is_anomaly_prediction'] = predictions
sns.scatterplot(
data = data,
x = 'x',
y = 'y',
hue = 'is_really_anomaly',
style="is_anomaly_prediction",
ax = axes[i]
)
axes[i].title.set_text(f"{str(parameter)}")
plt.tight_layout()
plt.show()
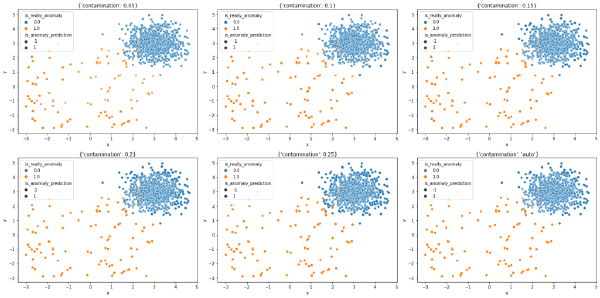
Como podemos ver, en este caso contamos con una cantidad de anomalías relativamente elevada (~10%). Así pues, valores bajos de contaminación (5%)suponen tener un problema de swamping, mientras que valores elevados de contaminación (25%) sufre de un problema elevado de masking.
Asimismo, vemos dos cuestiones interesantes:
- El mejor resultado parece darse con una contaminación del 10%.
- El resultado de fijar
contaminacion = "auto"también da buenos resultados, similares a los que obtendríamos con una contaminación del 15%.
Así pues, teniendo en cuenta lo anterior, la conclusión princiapl es que, si conoces el porcentaje de observaciones anómalas que suelen darse y estas se dan siempre a lo largo del tiempo (algo extraño), podrías llegar a fijar una contaminación de forma manual.
Sin embargo, bajo mi experiencia el anterior caso es bastante infrecuente y, en cualquier caso arriesgado, por lo que fijar una contaminación manual puede ser más seguro.
Perfecto, con esto ya conoces qué es Isolation Forest y cómo usar Isolation Forest en Python con Scikit-Learn. Sin embargo, y el impacto que tienen los principales parámetros de este modelo.
Sin embargo, ¿por qué deberíamos usar Isolation Forest (ya sea en Python u otro lenguaje), y no otro sistema de detección de anomalías? ¿Qué ventajas ofrece Isolation Forest, y qué desventajas? Veámoslo.
Ventajas y desventajas de Isolation Forest
Isolation Forest se diferencia de muchas otras técnicas de detección anomalías, ya que no se basa en medidas de distancia ni densidad. Esto le otorga una característica que, en mi opinión, es muy
En este sentido, estas son algunas de las ventajas de Isolation Forest:
- A diferencia de otros modelos de detección de anomalías que requieren ver todos los datos, Isolation Forest funciona muy bien cuando aplicamos sub-sampling, es decir, cuando usamos una muestra del dataset en lugar del dataset completo.
- Gracias al sub-sampling, Isolation Forest es un modelo rápido y eficiente, por lo que se puede usar en grandes datasets.
- Gracias a poder aplicar sub-sampling, Isolation Forest suele evitar los problemas de swamping, que, como hemos visto, ocurren al clasificar una observación anómala como no anómala. Este problema suele ocurrir cuando las observaciones anómalas están cerca de las no anómalas. Estos problemas suelen incrementarse cuanto mayor es el número de datos, por eso poder aplicar sub-sampling ayuda.
- Al igual que con el swamping, Isolation Forest suele evitar también los problemas de masking, que se dan cuando consideras a una observación no anómala como anómala. Esto se suele dar, también, gracias a la aplicación de sub-sampling.
- En comparación con los modelos de detección de anomalías basados en distancia, Isolation Forest funciona bien en datasets con muchas dimensiones, ya que no sufre del problema de data sparsity que sufren los modelos basados en distancias.
Dicho esto, también hay que tener en cuenta que Isolation Forest cuenta con algunas desventajas:
- Al igual que pasa con Random Forest, al ser un modelo basado en un bosque (conjutno de árboles), es difícil de interpretar.
- Puede que no funciona bien en un dataset con una gran cantidad de ruido, a menos que hagamos un buen tuning del mismo.
- Partiendo del punto anterior, no es un modelo que sea idóneo para todas las circunstancias y/o casos. Y es que, hay que decir que no hay un modelo de detección de anomalías que sea sistemáticamente mejor que otro. Todo dependerá del caso y de cómo se aplique.
En cualquier caso, parece claro que Isolation Forest es un muy buen método de detección de anomalias que, en mi punto de vista, debería estar en el toolset de todo Data Scientist.
Dicho esto, espero que este post te haya gustado. Si es así, te animo a suscribirte para estar al tanto de los posts que voy subiendo. En cualquier caso, ¡nos vemos en el siguiente!