En este post te voy a explicar, paso a paso, qué es un agente, qué elementos lo componen, patrones de diseño de agentes y todo lo que necesitas para poder crear tus agentes en LLM con LangGraph, una de las librerías más comunes para ello. ¿Te suena interesante? ¡Vamos con ello!
Qué es un agente y para qué sirve
Si entendemos la forma en la que trabajamos con los LLMs, en general solemos trabajar de dos maneras:
- Preguntar algo a un LLM y recibir una respuesta.
- Preguntar algo a un LLM, que este use una herramienta de la que le hemos provisto (como buscar en internet para sacar información) y nos da una respuesta.
Estos escenarios son flujos de control – o control flows, en inglés- lineale, es decir. Creo que la forma más fácil de entenderlo es mediante un esquema como el siguiente:
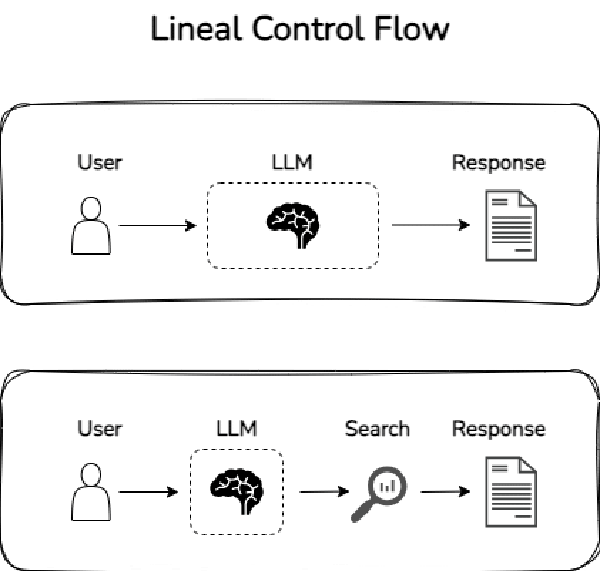
Si bien esta estructura es sencilla, es muy util para poder dar respuesta a preguntas relativamente sencillas. Sin embargo, aunque hay muchos elementos que se pueden responder mediante este tipo de flujos, hay muchos otros que requieren flujos más complejos. Ahí es donde entran los agentes.
Y es que, un agente, no es más que un LLM que tiene la capacidad de definir su propio flujo de control. Esta capacidad de definir un flujo de control puede ser desde algo muy sencillo, como elegir entre dos flujos o cursos de acción diferentes, hasta algo mucho más complejo, como ejecutar el proceso anterior de forma recursiva.
A continuación muestro un ejemplo de flujos de control no lineales, o lo que es lo mismo, dos sistemas de agentes:
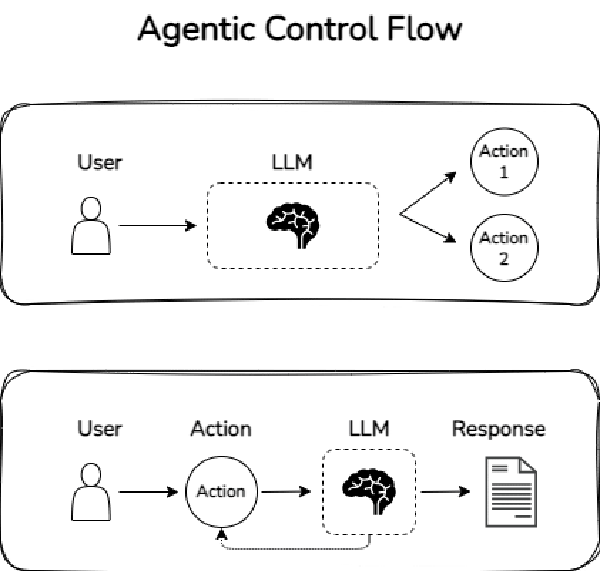
Como te puedes imaginar, los sistemas de agentes tienen la capacidad de poder dar respuesta a solicitudes mucho más complejas.
Entendido ahora lo que es un agente, veamos qué elementos contienen.
Componentes de los sistemas de agentes
1. Agente
Todo sistema de agentes debe contar con un agente. El agente es, en realidad, un LLM que recibe un prompt en el que se indica su objetivo, cómo debería responder, las herramientas de las que dispone, etc.
Asimismo, también se suele poder indicar una persona, es decir, definirle qué rol está jugando. Esto suele mejorar significativamente los resultados del propio agente.
En definitiva, el agente es un LLM al cual se le da contexto del problema, las herramientas a su alcance, su objetivo y todo lo que necesita para pdoer conseguirlo.
En un sistema de agentes, el LLM que actue de agente es un componente crítico. Por muy bien que esté montado el sistema, si el LLM subyacente al agente no es bueno (por ejemplo modelos 7B con quantización), entonces el resultado del sistema de agentes no será bueno.
2. Memoria
La memoria ofrece a lo agentes información sobre qué se ha realizado previamente para que así lo tenga en cuenta en sus respuestas. Existen dos enfoques de memoria:
- Memoria a corto plazo. Se trata de una memoria temporal para poder saber qué está haciendo u ocurriendo. Entiéndelo como el tomar notas en una reunión.
- Memoria a largo plazo. Se trata de una memoria a largo plazo, de las acciones realizadas previamente por el usuario. Tiene como objetivo entender patrones y aprender de tareas previas. Esto es algo que, por ejemplo, ChatGPT incorpora.
Aunque existan estos dos tipos de memoria no significa que todas las herramientas de LLM, a día de hoy, permitan implementarlos.
3. Herramientas
Los LLMs son muy potentes, pero no pueden hacerlo todo ellos solos. Para conseguir que hagan más cosas se les suele ofrecer herramientas –tools en inglés- con las que interactuar. Algunas herramientas típicas son funciones para acceder a APIs (para realizar búsquedas, por ejemplo), o para ofrecerle cierta funcionalidad extra.
Por ejemplo, un LLM sabe generar código SQL, pero no tiene la capacidad de acceder a mi base de datos para ejecutarlo. Si creamos una función de Python que reciba la query y ejecute la consulta en base de datos; y se la pasamos a nuestro LLM, podremos conseguir que ejecute código en base de datos y así darnos respuestas más certeras.
Patrones de diseño de sistemas de agentes
Los patrones de diseño –design patterns en inglés- son formas estandarizadas, probadas y eficientes de estructurar código para solucionar un problema. Al igual que en el mundo del desarrollo de software hay muchos patrones de diseño, también se han definido patrones de diseño en el mundo de los agentes.
A continuación, te detallaré los que considero los patrones de diseño más importantes, para que, cuando vayas a crear un agente, sepas cómo estructurarlo.
Los agentes son algo muy reciente, por lo que los patrones de diseño que presento no es algo consolidado ni estandarizado. Lo que indico es una lista curada de patrones de diseño que considero relevantes.
1. Reflexión
En ocasiones, los LLMs devuelven respuestas poco satisfactorias. Sin embargo, en esos casos, ofrecerles feedback sobre su trabajo les ayuda a mejorar en su respuesta. Así pues, la idea de la reflexión es implementar un sistema para que, el agente, reflexiones sobre el contenido que ha creado, pudiendo así mejorar la respuesta. Este sistema suele ser, en general, otro LLM que actúe como revisor del contenido del primero, como si de un escritor y su editor se tratara.
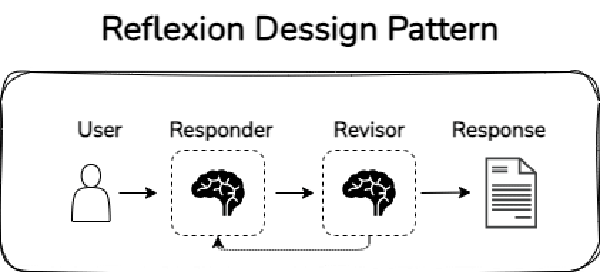
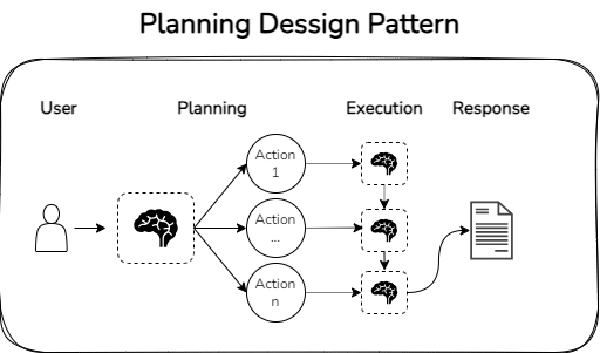
2. Planning
El planning consiste en definir una serie de tareas que deben realizarse para alcanzar el objetivo final. La idea por detrás es la de divide & conquer: dividir una tarea compleja en tareas más sencillas, de forma recursiva, hasta que las tareas son lo suficientemente sencillas como para que el LLM las pueda abordar.
Por ejemplo, si pides a un LLM que grafique un análisis que le solicitas en texto, para el cual debe crear código SQL, seguramente no sepa hacerlo. Sin embargo, el LLM seguramente sí sepa (siempre y cuando le ofrezcas el conocimiento y las herramientas) abordar tareas como: crear el código SQL para obtener los datos tal como lo necesitas, crear el código de Python para transformar y graficar los datos tal como lo has solicitado.
A continuación muestro un ejemplo de un patrón de diseño basado en el planning:
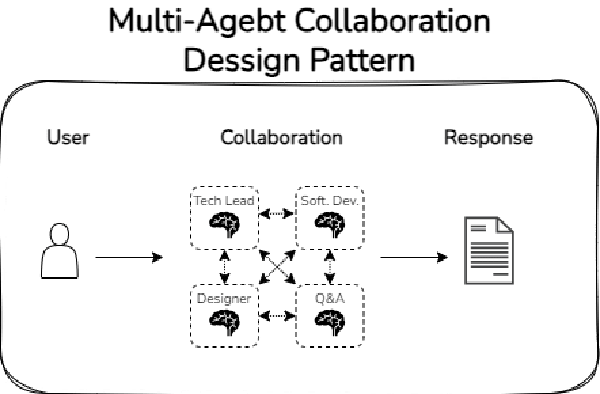
3. Colaboración multi-agente
La colaboración multi-agente consiste en replicar los procesos tal como lo haría una empresa en un proyecto: cuenta con diferentes personas especializadas que interactúan entre sí para llegar a una respuesta. Por ejemplo, el desarrollo de una página web incluye personas de diseño, de front-end, back-end, SEO, etc.
De la misma manera, un sistema de agentes basado en la colaboración multi-agente consiste en crear diferentes LLMs especializados, que interactúan entre sí para llegar a dar una respuesta al objetivo planteado. Al igual que en las empresas, esta colaboración puede adaptar muchas formas: puede haber una jerarquía, puede no haberla, puede haber solo roles especializados o incluir roles generalistas de control, etc.
A continuación, se muestra un ejemplo de dicho patrón de diseño:
Ahora que ya entiendes todos los conceptos de los agentes y diferente estrcuturas que pueden seguir, vamos a ver cómo puedes crear agentes con LangGraph.
Disclaimer: LangGraph no es la única solución para crear agentes, existen muchas más: CrewAI, AutoGPT, etc.
Instalación y prerequisitos de LangGraph para creación de agentes
Para poder instalar LangGraph vamos a necesitar dos cosas: instalar la librería y otras librerías de ayuda en Python y contar con un LLM al que podamos acceder de forma programática.
Para cubrir el segundo punto, deberemos conectarnos a un LLM que ofrezca Langchain (o, en su defecto, desarrollar nosotros la clase para hacer la conexión). No te preocupes, porque Langchain tiene integraciones con muchos LLMs: OpenAI, Antrophic, Google, Cohere, MistralAI, Ollama, etc. Puedes ver la lista completa aquí.
Una vez sepamos qué LLM vamos a querer instalar, deberemos seguir la guía de instalación, lo cual probablemente requiera de dos cosas:
- Guardar un token en un fichero
.env(recomendado) o como variable de entorno (no recomendado). - Instalar unas dependencias específicas.
En mi caso, usaré la API de OpenAI, por lo que tendré que ejecutar el siguiente comando:
pip install langchain_openai
La obtención y guardado de la API Key de Open AI no la redacto ya que viene explicado en muchos sitios y alargaría el blog de forma innecesaria.
Por otro lado, tendremos que instalar LangGraph y algunas otras librerías de langchain. En este caso la instalación es sencilla, simplemente deberás ejecutar el siguiente comando;
pip install langgraph langchain_core langchain_community
Ahora que ya tenemos LangGraph instalado, empecemos viendo los componentes básicos de para crear un agente en LangGraph.
Componentes básicos para crear un sistema de agente con LangGraph
Definición del estado del grafo
El estado de un grafo es un objeto, ya sea un TypedDict, un dataclass o un BaseModel de Pydantic, que permite ir guardando la información de ejecución de los diferentes nodos para que podamos ver cómo funciona el grafo y cómo se va construyendo la respuesta.
Un agente puede tener varios estados o solo uno. Lo más sencilo es crear un único estado que sea compartido, pero podríamos complejizarlo, creando un estado para la respuesta y un estado «privado» para la interacción interna entre nodos, por ejemplo.
En nuestro caso, vamos a crear un estado muy sencillo con Pydantic:
from pydantic import BaseModel
class GraphState(BaseModel):
graph_state: str
number_interactions: int = 0
verbose: bool = True
Definición del grafo
A la hora de crer un agente en LangGraph, empezaremos definiendo la clase StateGraph. Esta clase sirve para representar el grafo del agente que vamos a crear. En otras palabras, es la base sobre la que podemos ir añadiendo los distintos elementos. Y, como todo grafo, cuenta con dos elementos: nodos y aristas.
Ejemplo de definición de un grafo:
from langgraph.graph import StateGraph
graph = StateGraph(GraphState)
Definición de los nodos
Los nodos (node en inglés) en un grafo de LangGraph representan las acciones que un agente puede hacer, tales como añadir un modelo o una herramienta que los modelos pueden utilizar. Se puede añadir un nodo al grafo aplicando el método add_node de StateGraph.
Ejemplo de definir y añadir un nodo:
def greeting_node(state):
if state.verbose:
print("---- Greeting Node ----")
state.graph_state += "Hello! "
state.number_interactions += 1
return state
def normal_node(state):
if state.verbose:
print("---- Normal Node ----")
state.graph_state += "Today you should: "
state.number_interactions += 1
return state
def plan_node1(state):
if state.verbose:
print("---- Plan Node 1 ----")
state.graph_state += "go bowling!"
state.number_interactions += 1
return state
def plan_node2(state):
if state.verbose:
print("---- Plan Node 2 ----")
state.graph_state += "Netflix & chill"
state.number_interactions += 1
return state
graph.add_node("greeting_node", greeting_node)
graph.add_node("normal_node", normal_node)
graph.add_node("plan_node1", plan_node1)
graph.add_node("plan_node2", plan_node2)
Definición de las aristas
Las aristas (edge en inglés) son la forma de conectar los diferentes nodos y, por tanto, de mostrar las posibilidades del grafo de agente en LangGraph. En este sentido, existen tres tipos de aristas:
- Arista inicial: define la entrada del grafo a un nodo en concreto. El elemento de entrada será el que reciba el input que reciba el agente. Se define utilizando el método
set_entry_point. - Arista normal: define las conexiones entre diferentes nodos. Si hay una arista normal siempre se ejecutará el segundo nodo tras haber terminado la ejecución del primero. Se define utilizando el método
add_edge. - Arista condicional: en ocasiones te interesa que tras un nodo el agente eliga entre varias acciones, como repetir el paso anterior o terminar, tomar una acción u otra, etc. Se puede crear un nodo condicional con el método
add_conditional_edge, el cual requiere de los siguientes parámetros:- El nodo del cual nace la arista condicional.
- Un mapeo de los diferentes nodos a los que puede ir el nodo.
- Una función que permite determinar cuál de las opciones posibles debe tomar el nodo.
import random
from typing import Literal
from langgraph.graph import START, END
def decide_plan(state) -> Literal["plan_node1", "plan_node2"]:
return 'plan_node1' if random.random() < 0.5 else 'plan_node2'
graph.add_edge(START, "greeting_node")
graph.add_edge("greeting_node", "normal_node")
graph.add_conditional_edges("normal_node", decide_plan)
graph.add_edge("plan_node1", END)
graph.add_edge("plan_node2", END)
Compilación y Ejecución del Grafo
Al igual que ocurre en otros sistemas basados en grafos dirigidos (DAG) como Pytorch, el grafo computacional hay que compilarlo antes de ejecutarlo. Compilando pasamos de «crear» el grafo a «usar» el grafo. Para ello, simplemente tenemos que ejecutar el método compile de nuestro grafo, tal como muestro a conitnuación:
graph_compiled = graph.compile()
Una vez compila suele ser interesante visualizar el grafo apra comprobar que lo hemos creado de forma correcta. Hay varias formas de hacerlo, aunque lo más común suele ser crear el código mermaid y visualizarlo.
Así pues, vamos a visualizar el grado utilizando el método get_graph() y posteriormente draw_mermaid_png().
_ = (
graph_compiled
.get_graph()
.draw_mermaid_png(output_file_path='imgs/simple_graph.png')
)
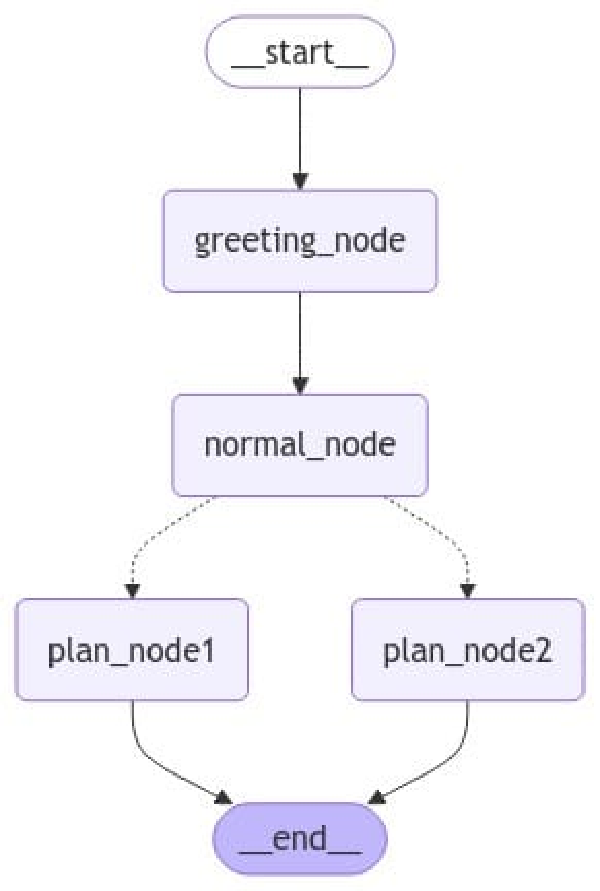
Por último, para ejecutar el grafo, debemos seguir dos pasos:
- Definir el o los estados base del agente, ya sea aplicando el mismo método con el que lo hemos creado (
TypedDict,dataclassoBaseModel) o pasando un diccionario de Python. - Ejecutar el agente usando el método
invokey pasando un diccionario el estado base.
base_dict = {"graph_state": "", "number_interactions": 0}
resp = graph_compiled.invoke(base_dict)
print(resp)
---- Greeting Node ----
---- Normal Node ----
---- Plan Node 1 ----
{'graph_state': 'Hello! Today you should: go bowling!', 'number_interactions': 3, 'verbose': True}
En este caso, como contamos con una arista condicional, el resultado del agente no tiene por qué ser siempre el mismo. Para comprobarlo, voy a ejecutar el grafo 3 veces. Además, para evitar los prints de cada paso, voy a fijar el estado a verbose = False.
base_state = {
"graph_state": "",
"number_interactions": 0,
"verbose": False
}
res = [graph_compiled.invoke(base_state) for _ in range(4)]
_ = [print(el['graph_state']) for el in res]
Hello! Today you should: go bowling!
Hello! Today you should: go bowling!
Hello! Today you should: go bowling!
Hello! Today you should: Netflix & chill
Como ves, contamos con un grafo que contiene: un nodo de entrada, un nodo normal, un nodo condicional, dos nodos de salida y que, además, va actualizando el estado del agente a cada paso.
Aún no he introducido ningún LLM, pero ya llegaremos a ello. Lo importante es que entiendas los componentes para crear un agente en LangGraph. Ahora que ya los conoces y entiendes (espero), voy a introducir dos elementos nuevos algo más complejos: las funciones y la memoria.
Componentes avanzados en un sistema de agente con LangGraph
Creación de Nodos basados en LLMs
En realidad, este no es un componente avanzado, es algo básico, pero con él la explicación previa sería algo más compleja. En cualquier caso, para crear un nodo que utilice un LLM vamos a necesitar:
- Definir el objeto Chat que esté disponible en Langchain para dicho LLM.
- Definir una función que llame al modelo.
Para el primer punto, yo voy a usar la API de OpenAI, por lo que usaré el objeto ChatOpenAI de Langchain. En mi caso, al tener guardada la API Key en el fichero .env, voy a utilizar la función load_dotenv para cargar dichas variables de entorno.
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
load_dotenv()
model = ChatOpenAI(model="gpt-4o")
Ahora que tenemos el modelo cargado, vamos a crear la función que nos permita interactuar con el LLM desde LangGraph. Vamos a crear una función sencilla que reciba los mensajes que aparezcan en el campo messages del estado y responda en consecuencia.
def call_model(state):
if state.verbose:
print("---- Call Model ----")
state.number_interactions += 1
state.messages = model.invoke(state.messages)
return state
Asimismo, vamos a crear una lista de mensajes previos para que nos sirvan de estado y el modelo responda sobre ello. Para ello usaré las clases AIMessage y HumanMessage de Langchain. Además, crearé también el estado del agente:
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
messages = [
AIMessage("What recipe do you want to learn to cook today?"),
HumanMessage("I would like to learn how to make french toasts.")
]
class GraphState(BaseModel):
messages: list
number_interactions: int = 0
verbose: bool = True
Por último, vamos a crear el grafo, incluyendo la función call_model como un nodo:
graph = StateGraph(GraphState)
graph.add_node("agent", call_model)
graph.add_edge(START, "agent")
graph.add_edge("agent", END)
agent = graph.compile()
_ = (
agent
.get_graph()
.draw_mermaid_png(output_file_path='imgs/llm_agent_graph.png')
)
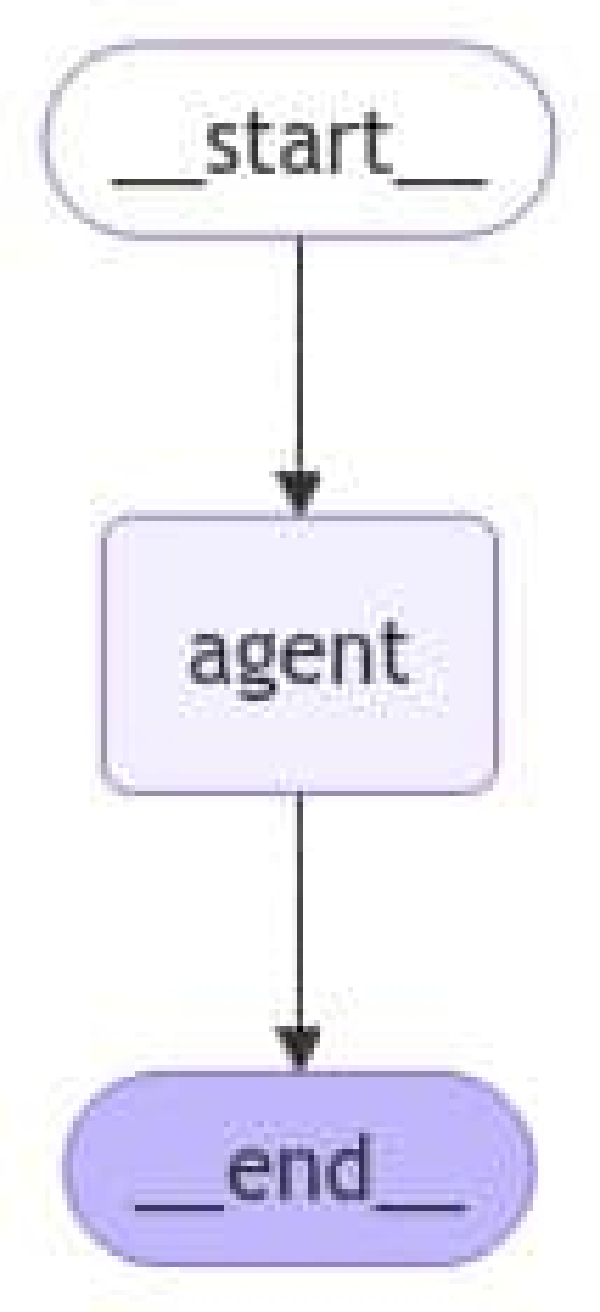
Como podemos ver, hemos creado un grafo muy sencillo que simplemente llama a nuestro LLM con los mensajes previos que hemos indicado. Veamos cómo funciona:
resp = agent.invoke({"messages": messages, "verbose": False})
print(resp['messages'].content[:500] + ' ...')
Making French toast is a simple and delicious process! Here's a classic recipe to get you started:
### Ingredients:
- 4 slices of bread (preferably slightly stale)
- 2 large eggs
- 1/2 cup milk
- 1 teaspoon vanilla extract
- 1/2 teaspoon ground cinnamon (optional)
- A pinch of salt
- Butter or oil for frying
- Maple syrup, powdered sugar, or fresh fruit for serving
### Instructions:
1. **Prepare the Egg Mixture:**
- In a shallow bowl or dish, whisk together the eggs, milk, vanilla extract, ...
Como ves, hemos creado un grafo muy sencillo de un único nodo en el que el nodo ejecutaba un LLM. Aunque esto parezca sencillo, es imoprtante conocer el funcionamiento para ir complejizándolo poco a poco.
En este sentido, ahora vamos a ver cómo ofrecer herramientas que el LLM puede usar para dar respuesta. Vamosa con ello.
Uso de Herramientas por parte de LLMs
Las herramientas son las funciones que podemos poner a disposición de nuestro nodo basado en LLM para realizar tareas y ampliar así sus capacidades. Entre los casos de uso de las herramientas encontramos acceder a APIs y a bases de datos, entre otras.
A modo de ejemplo, voy a crear una herramienta que sirva como calculadora de valores factoriales. Para ello, voy a crear una serie de funciones que el LLM pueda usar como herramientas. Concretamente voy a crear una función llamada factorial que calcula el factorial y una función llamada multiply, que multiplica dos valores.
Para que el modelo sepa usar las funciones es necesario rellenar los docstrings de las mismas.
from functools import lru_cache
from langchain_core.tools import tool
@lru_cache(maxsize=None)
def factorial(n: int) -> int:
return n * factorial(n - 1) if n else 1
def calculate_factorial(n: int) -> int:
"""Calculate the factorial of n
Args:
n: Value to calculate the factorial of
Returns:
int: Result of the factorial calculation
"""
return factorial(n)
def multiply(a: int, b: int) -> int:
"""Multiply the input a b y b
Args:
a: First number to multiply
b: Second number to multiply
Returns:
int: Result of the multiplication
"""
return a * b
Teniendo ya las funciones, para que estas sean accesibles por el LLM, hay que aplicar el método bind_tools sobre el propio LLM, tal como muestro a continuación:
tools = [multiply, calculate_factorial]
model = ChatOpenAI(model="gpt-4o")
model_with_tools = model.bind_tools(tools)
Hecho esto, podemos crear el nodo del agente, el cual aplicará el método invoke,como hemos hecho previamente. Sin embargo, a diferencia de como lo hemos hecho antes, ahora vamos a darle algo de contexto al LLM dentro del propio nodo, para que sepa interactuar con las herramientas de forma correcta:
def math_llm(state):
msg_content = "You are a helpful math assistant that explains what it does."
message = [SystemMessage(content=msg_content)] + state['messages']
return {"messages": model_with_tools.invoke(message)}
Ahora que tenemos tanto las herramientas como el LLM que sabe usarlas, tenemos que indicarle todo esto a LangGraph. Esto pasa por:
- Añadir el LLM que usa herramientas como un nodo (tal como hemos hecho previamente con el nodo basado en un LLM).
- Añadir las herramientas al propio grafo. Esto lo haremos haciendo un wrap de las herramientas con la clase
ToolNode.
from langgraph.prebuilt import tools_condition, ToolNode
from langgraph.graph import MessagesState
graph = StateGraph(MessagesState)
graph.add_node("math_llm", math_llm)
graph.add_node("tools", ToolNode(tools))
Finalmente, vamos a crear las aristas. Para ello, tenemos que tener en mente que, tras el uso de una herramienta, el resultado siempre volverá al asistente, para que compruebe si con ese nuevo resultado puede dar, o no, respuesta. Esto nos puede llevar a dos escenarios:
- Con el resultado obtenido de la herramienta, el LLM de respuesta. Esto implicaría que fuese el final (o siguiente etapa).
- El LLM vuelva a llamar a la misma herramienta (o alguna de las otras herramientas a su alcance) para poder dar respuesta. En este caso, el LLM volverá a llamar a la herramienta.
Como ves, esta es una lógica que es muy común (ocurre siempre que se usa una herramienta), pero que no es tan intuitiva. Es por ello, que en LangGraph cuentan con la función tools_condition, la cual implementa dicha lógica para facilitarnos un poco la vida. Esta función comprueba si la ejecución anterior es generada por una función o por el LLM: en caso de que el resultado sea generado por un LLM, lleva al END node, y, sino, vuelve a llamar a la función.
A modo resumen, al usar herramientas hay que tener en cuenta dos cosas:
- Siempre habrá una arista de la herramienta al LLM.
- Un LLM con herramienta puede, o no, llamar a la herramineta.
Dicho esto, vamos a añadir las aristas de nuestro grafo.
graph.add_edge(START, "math_llm")
graph.add_edge("tools", "math_llm")
graph.add_conditional_edges("math_llm", tools_condition)
Finalmente, vamos a compilar el grafo, visualizarlo y ejecutarlo.
agent = graph.compile()
_ = (
agent
.get_graph()
.draw_mermaid_png(output_file_path='imgs/math_tool_agent.png')
)
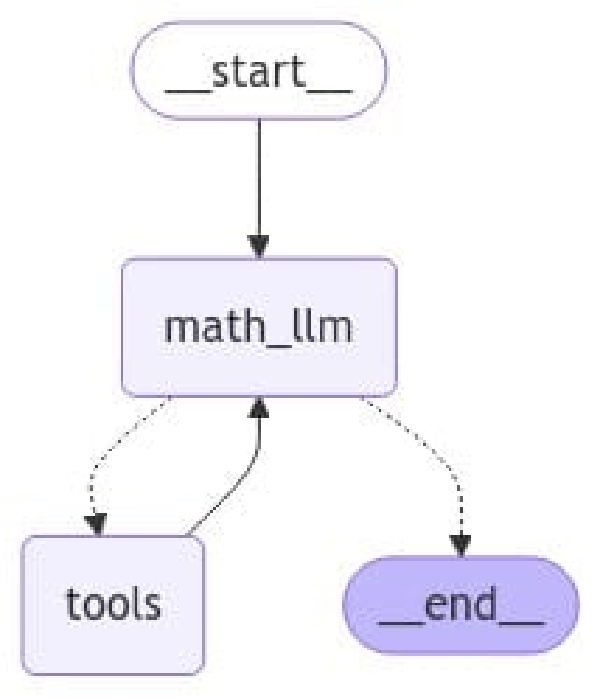
Visto el flujo, vamos a ver si funciona correctamente:
msg_content = "Calculate 5 factorial and multiply it by 3."
state = {"messages": [HumanMessage(msg_content)]}
resp = agent.invoke(state)
for message in resp['messages']:
message.pretty_print()
================================[1m Human Message [0m=================================
Calculate 5 factorial and multiply it by 3.
==================================[1m Ai Message [0m==================================
Tool Calls:
calculate_factorial (call_R33t6J4m2lQyxYREGl8la3xh)
Call ID: call_R33t6J4m2lQyxYREGl8la3xh
Args:
n: 5
multiply (call_HVLQBJjhOdK316p6JTXWu4eN)
Call ID: call_HVLQBJjhOdK316p6JTXWu4eN
Args:
a: 5
b: 3
=================================[1m Tool Message [0m=================================
Name: calculate_factorial
120
=================================[1m Tool Message [0m=================================
Name: multiply
15
==================================[1m Ai Message [0m==================================
The factorial of 5 is 120. When you multiply 120 by 3, the result is 360.
Ahora que ya sabemos cómo hacer que nuestro agente interactúe con herramientas, vamos a ir un paso más allá, añadiendo memoria a nuestro agente.
Añadir memoria al sistema de agente en LangGraph
Como hemos visto al principio de este post, cuando hablamos de agentes (ya sea en LangGraph o fuera de ello), existen dos tipos principales de memoria:
- La memoria a corto plazo, que es aquella que permite conocer las acciones del agente durante su ejecución.
- La memoria a largo plazo, que permite guardar memoria ente diferentes intereacciones con el agente.
Si nos centramos en la memoria a corto plazo, hay que tener en cuenta que, cuando trabajamos con agentes en LangGraph, por defecto, el estado de cada nodo es temporal. Es decir, cuando un nodo termina de ejecutar, no se almacena el input del nodo y el output que ha dado.
Para evitarlo, LangGraph permite añadir memoria a corto plazo a tu agente. Esta memoria guarda la información en hilos (threads) lo cual permite guardar diferentes conversaciones en una misma sesión. Sería como cuando escribes hilos en Twitter / X: todos los mensajes, quedan agrupados de una manera por un hilo (o thread). La forma que LangGraph tiene de guardar estos hilos es mediante checkpointers.
Así pues, la memoria se suele utilizar de dos formas:
- Para editar la lista de mensajes, eliminando los mensajes antiguos.
- Para hacer un resumen de los mensajes antiguos, de tal forma que el agente responda con los mensajes nuevos y un resumen de los antiguos. Esta suele ser la técnica más utilizada.
Además, sobre la propia memoria hay dos formas de gestionarla:
- Memoria no persistente, en la que, cuando se reinicia la sesión, la memoria desaparece. Puedes implementar esta memoria usando el objeto
MemorySaverdel módulolanggraph.checkpoint.memory. - Memoria persistente, es aquella que se va guardando en una base de datos (como
sqlite), de tal forma que esté disponible cuando la sesión se reinicie. Puedes implementar esta memoria usando el objetoSqliteSaverdel módulolanggraph.checkpoint.sqlite.
Para utilizar la memoria con
sqlitedeberás instalar la siguiente libreríalanggraph-checkpoint-sqlite
Veamos un ejemplo de memoria muy sencillo: cuando le das contexto al agente en una pregunta, y le vuelves a responder al agente por otro caso, pero sin ofrecer contexto. Para ello, voy a crear un agente ReAct que tenga acceso a buscar en internet.
from langchain_community.tools.ddg_search import DuckDuckGoSearchRun
tools = [DuckDuckGoSearchRun()]
model = ChatOpenAI(model="gpt-4o")
model_with_tools = model.bind_tools(tools)
def weather_llm(state):
msg_content = "You are a helpful weather assistant"
message = [SystemMessage(content=msg_content)] + state['messages']
return {"messages": model_with_tools.invoke(message)}
graph = StateGraph(MessagesState)
graph.add_node("weather_llm", weather_llm)
graph.add_node("tools", ToolNode(tools))
graph.add_edge(START, "weather_llm")
graph.add_edge("tools", "weather_llm")
graph.add_conditional_edges("weather_llm", tools_condition)
agent = graph.compile()
_ = (
agent
.get_graph()
.draw_mermaid_png(output_file_path='imgs/weather_tool_agent.png')
)
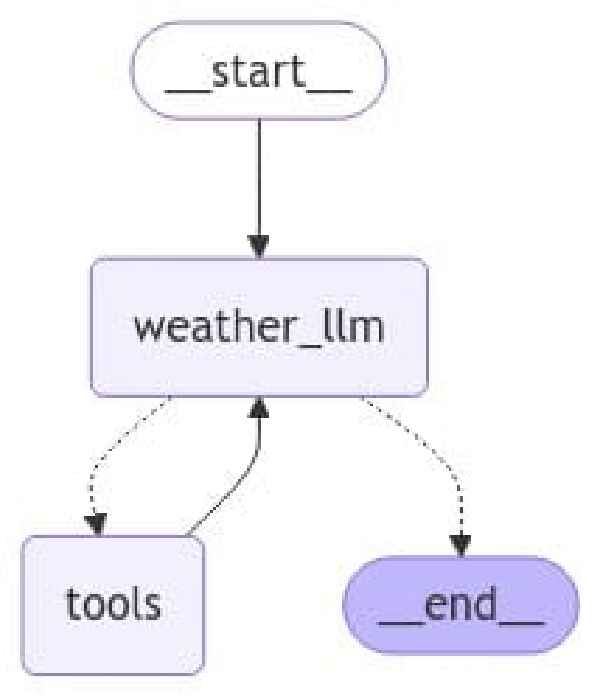
Como ves, la creación del agente con LangGraph no ha cambiado. Veamos qué responde cuando solicitamos información del clima de mi ciudad natal, Bilbao:
agent.invoke(
{"messages": [HumanMessage("What is the weather in Bilbao today?")]}
)
{'messages': [AIMessage(content='The weather in Bilbao today is expected to be mostly sunny with a few clouds. The temperature highs are likely to reach around 70°F (approximately 21°C). There is a light breeze blowing at 4 to 8 mph, from the south in the morning and from the north in the afternoon.', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 62, 'prompt_tokens': 318, 'total_tokens': 380, 'completion_tokens_details': {'reasoning_tokens': 0}, 'prompt_tokens_details': {'cached_tokens': 0}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_45cf54deae', 'finish_reason': 'stop', 'logprobs': None}, id='run-d652673b-67aa-42d1-b76e-472baf15ae3c-0', usage_metadata={'input_tokens': 318, 'output_tokens': 62, 'total_tokens': 380})]}
Como vemos, el agente ha respondido correctamente. Ahora preguntémoles por otra ciudad, como Barcelona, a ver qué responde:
agent.invoke({"messages": [HumanMessage("what about Barcelona?")]})
{'messages': [HumanMessage(content='what about Barcelona?', additional_kwargs={}, response_metadata={}, id='b9d93d31-ab2f-4e3b-8511-cdc08c783321'),
AIMessage(content='Could you please provide more details about what you would like to know regarding Barcelona? Are you interested in the weather, current events, travel information, or something else?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 34, 'prompt_tokens': 84, 'total_tokens': 118, 'completion_tokens_details': {'reasoning_tokens': 0}, 'prompt_tokens_details': {'cached_tokens': 0}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_159d8341cc', 'finish_reason': 'stop', 'logprobs': None}, id='run-60f82d06-2266-444b-a3ff-c572e9cee34e-0', usage_metadata={'input_tokens': 84, 'output_tokens': 34, 'total_tokens': 118})]}
Como ves, nuestro agente de LangGraph no ha sido capaz de entender que cuando le preguntábamos sobre Barcelona, en realidad, le estábamos preguntado por el clima en Barcelon. Esto es porque nuestro modelo no tiene memoria.
Así pues, vamos a crear una base de datos con sqlite para darle memoria a nuestro agente y ver cómo responde cuando le ofrecemos el histórico de la conversación como input. Vamos a empezar creando nuestra base de datos:
import sqlite3
from langgraph.checkpoint.sqlite import SqliteSaver
conn = sqlite3.connect('memory.db', check_same_thread=False)
memory = SqliteSaver(conn)
Ahora vamos a rehacer el agente, y vamos a definir el hilo sobre el cual se van a ir guardando los mensajes:
config = {"configurable": {"thread_id": "2"}}
from langchain_community.tools.ddg_search import DuckDuckGoSearchRun
tools = [DuckDuckGoSearchRun()]
model = ChatOpenAI(model="gpt-4o")
model_with_tools = model.bind_tools(tools)
def weather_llm(state):
msg_content = "You are a helpful weather assistant"
message = [SystemMessage(content=msg_content)] + state['messages']
return {"messages": model_with_tools.invoke(message)}
graph = StateGraph(MessagesState)
graph.add_node("weather_llm", weather_llm)
graph.add_node("tools", ToolNode(tools))
graph.add_edge(START, "weather_llm")
graph.add_edge("tools", "weather_llm")
graph.add_conditional_edges("weather_llm", tools_condition)
agent = graph.compile(checkpointer=memory)
Por último, vamos a repetir las dos mismas preguntas que le hemos hecho antes, a ver qué responde:
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
agent.invoke(
{"messages": [HumanMessage("What is the weather in Bilbao today?")]},
config=config
)
{'messages': [HumanMessage(content='What is the weather in Bilbao today?', additional_kwargs={}, response_metadata={}, id='71504012-2e89-472f-a20d-6056966ab8e3'), AIMessage(content='The weather in Bilbao today, October 26, 2023, is characterized by heavy rain and light rain throughout the day, with temperatures ranging from a high of 20°C to a low of 13°C.', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 45, 'prompt_tokens': 1505, 'total_tokens': 1550, 'completion_tokens_details': {'reasoning_tokens': 0}, 'prompt_tokens_details': {'cached_tokens': 0}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_45cf54deae', 'finish_reason': 'stop', 'logprobs': None}, id='run-a91f61d6-f32c-4de9-accf-069e3be2ed7f-0', usage_metadata={'input_tokens': 1505, 'output_tokens': 45, 'total_tokens': 1550})]}
Como podemos ver, el agente ha respondido con datos de clima. Es cierto que los datos que da no son datos actualizados. Esto es porque no le hemos dado una herramienta específica para ello. En cualquier caso, veamos ahora a ver si cuando le preguntamos por Barcelona, responde o no sobre el clima:
agent.invoke(
{"messages": [HumanMessage("what about Barcelona?")]},
config=config
)
{'messages': [HumanMessage(content='What is the weather in Bilbao today?', additional_kwargs={}, response_metadata={}, id='71504012-2e89-472f-a20d-6056966ab8e3'),
AIMessage(content='The weather in Bilbao today, October 26, 2023, is characterized by heavy rain and light rain throughout the day, with temperatures ranging from a high of 20°C to a low of 13°C.', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 45, 'prompt_tokens': 1505, 'total_tokens': 1550, 'completion_tokens_details': {'reasoning_tokens': 0}, 'prompt_tokens_details': {'cached_tokens': 0}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_45cf54deae', 'finish_reason': 'stop', 'logprobs': None}, id='run-a91f61d6-f32c-4de9-accf-069e3be2ed7f-0', usage_metadata={'input_tokens': 1505, 'output_tokens': 45, 'total_tokens': 1550}),
HumanMessage(content='what about Barcelona?', additional_kwargs={}, response_metadata={}, id='18186736-53ff-4be5-aafb-66d9e3af068f'),
AIMessage(content='In Barcelona today, October 26, 2023, the weather is mild and pleasant with daytime temperatures around 24°C (75.2°F), reaching a maximum of 26°C (78.8°F). However, since October is generally a rainy month in Barcelona, some rainfall may occur.', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 62, 'prompt_tokens': 1561, 'total_tokens': 1623, 'completion_tokens_details': {'reasoning_tokens': 0}, 'prompt_tokens_details': {'cached_tokens': 1408}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_45cf54deae', 'finish_reason': 'stop', 'logprobs': None}, id='run-0a6d4fa9-2b8d-4bf5-b64b-55ed7ba2da04-0', usage_metadata={'input_tokens': 1561, 'output_tokens': 62, 'total_tokens': 1623})]}
Como puedes ver, en este caso sí ha respondido sobre el clima, porque guarda la memoria de las conversaciones previas que ha tenido.
Parar la ejecución de un agente para actualizar estados
Hay ocasiones, como la que veremos más adelante con Human-in-the-loop en la que nos interesa parar un nodo, ya sea para debuggear o para poder actualizar uno de los resultados de sus nodos. A esto se le llama añadir breakpoints al agente. Para poder añadir breakpoints a nuestro agente necesitamos cumplir dos condiciones:
- Indicarle al grafo antes o después de qué nodo queremos que se pare. Esto lo podemos conseguir usando los parámetros
interrupt_beforeeinterrupt_afterdel métodocompile. - Interactuar con el agente teniendo la opción de obtener información actualizada de ejecución. Esto lo conseguimos llamando al agente usando el método
streamoastream(en función de si queremos que la llamada sea síncrona o asíncrona) en lugar de utilizar el métodoinvoke.
Esta no es la única manera de conseguir aplicar breakpoints en un agente, existen otras maneras, pero en mi opinión son chapuzas que hay que evitar.
Sobre este último punto, al utilizar streams, existen dos formas principales de realizar el stream:
- Obtener todos los resultados de vuelta. Sirve cuando quieres actualizar uno de los estados del agente y se consigue definiendo el parámetro
stream_mode="values". - Obtener solo los resultados actualizados. Sirve cuando quieres obtener el nodo y el valor del nodo que se ha actualizado y se consigue definiendo el parámetro
stream_mode="updates".
Esta sección ya lleva mucha información nueva, así que vamos a crear un grafo sencillo para entenderlo mejor:
from langgraph.checkpoint.memory import MemorySaver
graph = StateGraph(MessagesState)
def step1(state):
n_chars = len(state['messages'][-1].content)
return {'messages': 'Previous message had ' + str(n_chars) + ' characters.'}
def step3(state):
n_chars = len(state['messages'][-1].content)
return {'messages': 'Last message had ' + str(n_chars) + ' characters.'}
graph.add_node("step1", step1)
graph.add_node("step2", lambda x: {'messages': 'This is step 2' })
graph.add_node("step3", step3)
graph.add_node("step4", lambda x: {'messages': 'The end!' })
graph.add_edge(START, "step1")
graph.add_edge("step1", "step2")
graph.add_edge("step2", "step3")
graph.add_edge("step3", "step4")
graph.add_edge("step4", END)
memory = MemorySaver()
agent = graph.compile(
checkpointer= memory,
interrupt_before = ['step2'], interrupt_after = ['step3']
)
_ = (
agent
.get_graph()
.draw_mermaid_png(output_file_path='imgs/breakpoint_sequential_graph.png')
)
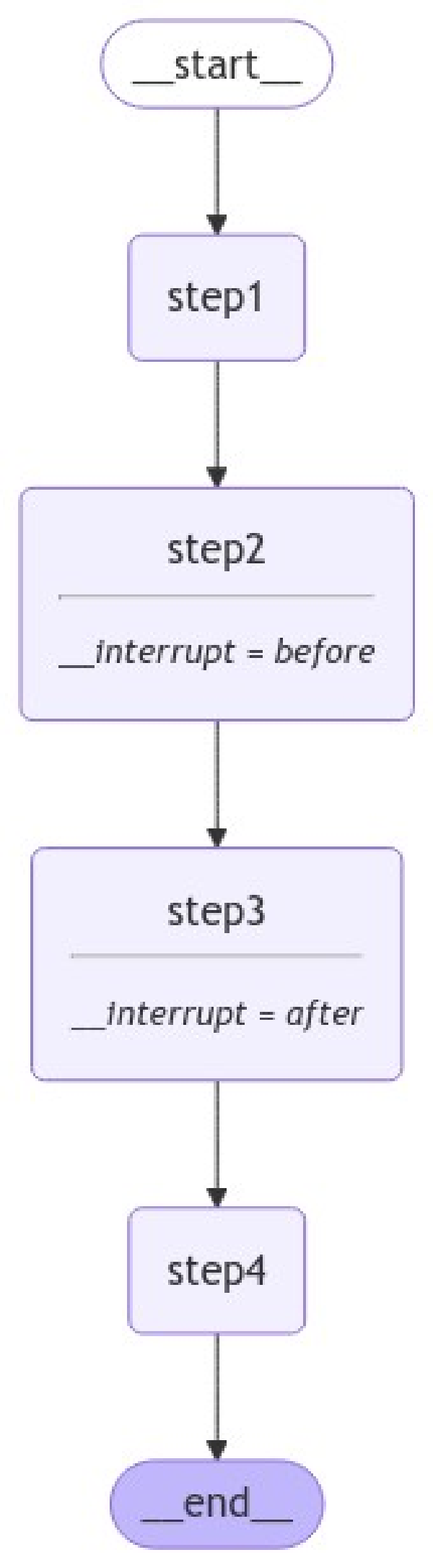
Como vemos, nuestro agente tiene dos interrupciones: antes de step2 y después de step3. Si ejecutamos nuestro agente, se ejecutará hasta el step2, pero este no se ejecutará. Veámoslo:
thread = {"configurable": {"thread_id": "1"}}
agent_input = {"messages": ["Example message"]}
for event in agent.stream(agent_input, thread, stream_mode="values"):
print(event['messages'][-1].content)
Example message
Previous message had 15 characters.
Ahora el agente se ha parado antes de step_2, es decir, que seguimos en step_1. Así pues, si, por ejemplo, el resultado que nos ha devuelto step_1 no nos ha gustado, podríamos actualizar el input que ha recibido ese nodo. Esto lo podemos hacer pasando un nuevo mensaje a stream. Este mensaje se trasladará al nodo en el que estamos, en nuestro caso, step_1. Ejemplo:
for event in agent.stream({'messages': 'short text'}, thread, stream_mode="values"):
print(event['messages'][-1].content)
short text
Previous message had 10 characters.
Como vemos, se ha vuelto a ejecutar el step_1, esta vez con el nuevo mensaje. Como resultado, la respuesta ha pasado de ser 15 a ser 10. Esta forma de hacer breakpoints nos permite reejecutar ciertos nodos hasta conseguir un resultado que nos parezca interesante.
En cualquier caso, supongamos que el agente ha respondido satisfactoriamente. Aún quedan más nodos por ejecutar. Podemos ejecutarlos llamando el método stream y pasando el valor None:
for event in agent.stream(None, thread, stream_mode="values"):
print(event['messages'][-1].content)
Previous message had 10 characters.
This is step 2
Last message had 14 characters.
Como ves, se han ejecutado todos los nodos hasta llegar a step3. Tras ejecutar dicho nodo, la ejecución se ha parado. Si volvemos a ejecutarlo veremos que, como el breakpoint se da en el step3, si pasamos un nuevo valor volverá a ejecutar step3. Veámoslo pasando un texto muy corto:
for event in agent.stream({'messages':'End.'}, thread, stream_mode="values"):
print(event['messages'][-1].content)
End.
Previous message had 4 characters.
Como vemos, la respuesta que hemos obtenido es diferente. Finalmente, podríamos pedir que siga ejecutando para que termine de ejecutar todos los nodos:
for event in agent.stream(None, thread, stream_mode="values"):
print(event['messages'][-1].content)
Previous message had 4 characters.
This is step 2
Last message had 14 characters.
Perfecto, ahora que ya sabes cómo añadir breakpoints en el agente, vamos al último concepto por aprender: añadir feedback por parte del usuario.
Cómo añadir feedback personal (Human in the loop)
Añadir feedback al resultado que está generando el agente es importante, especialmente cuando te dedicas a crear arquitecturas grandes y complejas, ya que permite ir corrigiendo el comportamiento del agente en caso de que se equivoque. A este proceso se le llama human-in-the-loop.
Aunque en LangGraph hay diferentes formas de dar feedback al agente, la forma que a mí más me gusta y más limpia me parece es creando un nodo dummy que no hace nada y que se ejecuta después del paso que quieras. Utilizaremos dicho nodo para poder aplicar una actualización de nuestro agente, aplicando un breakpoint en el nodo.
Dicho así suena complejo, creo que la mejor forma de entenderlo es viéndolo. Así pues, vamos a replicar la arquitectura del agente de LangGraph que llamaba a funciones para hacer cálculos matemáticos y vamos a añadir el human in the loop. Los principales cambios serán:
- Crear una función llamada
human_feedbacky un nodo que llame a dicha función. - Fijar el nodo
humna_feedbackal empezar, después de la herramienta y después del llm que utiliza las herramientas.
Dicho esto, la arquitectura queda de la siguiente manera
Por no repetir el código, no vuelvo a definir las funciones que hayan sido definidas previamente.
# Create the LLM with tools
tools = [multiply, calculate_factorial]
model = ChatOpenAI(model="gpt-4o")
model_with_tools = model.bind_tools(tools)
def route_feedback(state):
if state["messages"][-1].type == 'ai':
if len(state["messages"][-1].tool_calls) == 0:
return END
else:
return "tools"
else:
return "math_llm"
# Define the nodes
graph = StateGraph(MessagesState)
graph.add_node("math_llm", math_llm)
graph.add_node("feedback", lambda x: None)
graph.add_node("tools", ToolNode(tools))
# Definte the edges
graph.add_edge(START, "math_llm")
graph.add_edge("math_llm", "feedback")
graph.add_conditional_edges("feedback", route_feedback)
graph.add_edge("tools", "feedback")
memory = MemorySaver()
agent = graph.compile(
interrupt_before=["feedback"],
checkpointer=memory
)
_ = (
agent
.get_graph()
.draw_mermaid_png(output_file_path='imgs/human_feedback_agent.png')
)
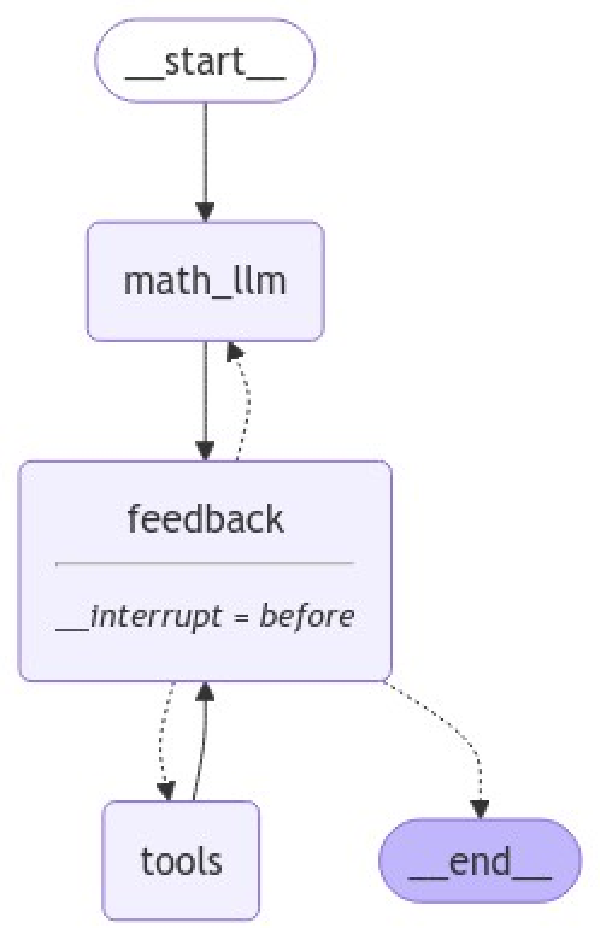
Como ves, tenemos una arquitectura de agente algo diferente a lo habitual, ya que contiene el nodo dummy. Ahora vamos a ejecutar el agente hasta que el último mensaje sea un mensaje sea un uso de herramienta o del agente:
initial_input = {
"messages": "Get the result of 5 factorial and multiply it by 5."
}
thread = {"configurable": {"thread_id": "1"}}
# Run the graph until the first interruption
for event in agent.stream(initial_input, thread, stream_mode="values"):
event['messages'][-1].pretty_print()
================================[1m Human Message [0m=================================
Get the result of 5 factorial and multiply it by 5.
==================================[1m Ai Message [0m==================================
Tool Calls:
calculate_factorial (call_LTcYP2RvISdORzuHJ0oMtpnv)
Call ID: call_LTcYP2RvISdORzuHJ0oMtpnv
Args:
n: 5
multiply (call_eaJDC9A3w2Vpj08VysqqB2lL)
Call ID: call_eaJDC9A3w2Vpj08VysqqB2lL
Args:
a: 5
b: 5
Ahora vemos cómo se ha parado la ejecución tras el evento de llamar a las herramientas.
La llamada es correcta, así que podemos dejar que siga ejecutando el agente.
for event in agent.stream(None, thread, stream_mode="values"):
event['messages'][-1].pretty_print()
==================================[1m Ai Message [0m==================================
Tool Calls:
calculate_factorial (call_LTcYP2RvISdORzuHJ0oMtpnv)
Call ID: call_LTcYP2RvISdORzuHJ0oMtpnv
Args:
n: 5
multiply (call_eaJDC9A3w2Vpj08VysqqB2lL)
Call ID: call_eaJDC9A3w2Vpj08VysqqB2lL
Args:
a: 5
b: 5
=================================[1m Tool Message [0m=================================
Name: multiply
25
Asimismo, ha vuelto a pararse tras haber ejecutado la operación. Supongamos que la respuesta correcta no es 600, sino 100. Podríamos pedir que vuelva a ejecutar el proceso:
for event in agent.stream({"messages": "Calculate the result of 3 factorial and multiply by 5"}, thread, stream_mode="values"):
event['messages'][-1].pretty_print()
================================[1m Human Message [0m=================================
Calculate the result of 3 factorial and multiply by 5
==================================[1m Ai Message [0m==================================
Tool Calls:
calculate_factorial (call_tsADVnHidWNW1aRwEpdmSvfR)
Call ID: call_tsADVnHidWNW1aRwEpdmSvfR
Args:
n: 3
multiply (call_XzMp88YUCq0PHUcImqRHZR2h)
Call ID: call_XzMp88YUCq0PHUcImqRHZR2h
Args:
a: 3
b: 5
Por último, vamos a terminar la ejecución del agente, pasando None para que siga ejecutando:
for event in agent.stream(None, thread, stream_mode="values"):
event['messages'][-1].pretty_print()
==================================[1m Ai Message [0m==================================
Tool Calls:
calculate_factorial (call_tsADVnHidWNW1aRwEpdmSvfR)
Call ID: call_tsADVnHidWNW1aRwEpdmSvfR
Args:
n: 3
multiply (call_XzMp88YUCq0PHUcImqRHZR2h)
Call ID: call_XzMp88YUCq0PHUcImqRHZR2h
Args:
a: 3
b: 5
=================================[1m Tool Message [0m=================================
Name: multiply
15
Como ves, con un cambio sencillo somos capaces de corregir a nuestro agente, en el uso de herramientas y en las conclusiones que saca con ellas. Este ha sido un ejemplo sencillo, pero la idea es poder usar estos conceptos para aplicarlos a tareas más complejas.
Ahora que ya conoces tanto los componentes básicos como los componentes avanzados en la creación de un agnete, vamos al siguiente nivel: creación de sistemas multiagente.
Cómo crear un sistema de agente multiagente con LangGraph
Los agentes por sí solos son interesantes, pero no suponen un cambio crítico. Crear sistemas con diferentes agentes sí que tiene un impacto significativo. Como hemos visto al principio del tutorial, existen diferentes formas de organizar a los agentes (jerarquía, sin jerarquía, especialistas vs generalistas, etc.). En este caso yo voy a crear un ejemplo para que aprendas a crear sistemas de agente multiagente en LangGraph.
Existen soluciones más allá de LangGraph enfoacadas a la genereación de sistemas de agentes multiagente (como crew.ai) que pueden resultar mucho más rápidas y sencillas. Sin embargo, creo que la complejidad de LangGraph añade un conocimiento más profundo del proceso, lo cual es interesante.
Concretamente, vamos a crear un sistema de agente que nos permita aprender cuestiones técnicas. Para ello, vamos a contar con dos tipos de agentes:
- Researches: es el agente encargado de buscar el contenido en internet.
- Explainer: es el agente encargado de resumir y hacer entendible la información del usuario.
Vamos a empezar creando el agente del researcher:
from langchain_community.tools.ddg_search import DuckDuckGoSearchRun
# Create researcher agent
research_tools = [DuckDuckGoSearchRun()]
model = ChatOpenAI(model="gpt-4o")
research_model_with_tools = model.bind_tools(research_tools)
def researcher_llm(state):
msg_content = ("You are a helpful learning assistant. You search on "
"the internet and provide the answer using different sources. "
"You also cite those sources.")
message = [SystemMessage(content=msg_content)] + state['messages']
return {"messages": research_model_with_tools.invoke(message)}
researcher_graph = StateGraph(MessagesState)
researcher_graph.add_node("researcher", researcher_llm)
researcher_graph.add_node("tools", ToolNode(research_tools))
researcher_graph.add_edge(START, "researcher")
researcher_graph.add_conditional_edges("researcher", tools_condition)
researcher_agent = researcher_graph.compile()
user_input = "What is the best way to creat a RAG system?"
resp = researcher_agent.invoke({"messages": [HumanMessage(user_input)]})
print(resp['messages'][-1].content[:500] + ' ...')
Creating a RAG (Retrieval-Augmented Generation) system involves integrating information retrieval techniques with natural language generation models. This approach is particularly useful for generating more accurate and contextually relevant responses by leveraging external knowledge sources. Here's a step-by-step guide to creating a RAG system:
1. **Understand the Components**:
- **Retriever**: The component that searches for relevant documents or information from a knowledge base or databa ...
Como vemos el agente genera respuesta, pero puede que dicha respuesta no sea del todo sencilla de entender. Aquí es donde entra en juego nuestro segundo agente. Este explainer explicará conceptos complejos de manera sencilla utilizando alegorías.
from langchain_community.tools.ddg_search import DuckDuckGoSearchRun
# Create researcher agent
explainer_model = ChatOpenAI(model="gpt-4o")
def explainer_llm(state):
msg_content = ("You are a helpful teacher. You explain any topic, "
"regardless how difficult it is, in a very simple way. Your "
"students are children and they do not understand many things."
" To do so, you use examples, stories and allegories as needed."
"Look on the internet any concept you don't understand.")
message = [SystemMessage(content=msg_content)] + state['messages']
return {"messages": explainer_model.invoke(message)}
explainer_graph = StateGraph(MessagesState)
explainer_graph.add_node("explainer", explainer_llm)
explainer_graph.add_node("tools", ToolNode(research_tools))
explainer_graph.add_edge(START, "explainer")
explainer_graph.add_conditional_edges("explainer", tools_condition)
explainer_agent = explainer_graph.compile()
user_input = "Explain the concept of entropy in physics."
resp = explainer_agent.invoke({"messages": [HumanMessage(user_input)]})
print(resp['messages'][-1].content[:500] + ' ...')
Alright, kiddos! Let's dive into the world of physics and talk about something called "entropy." Imagine you have a big box of colorful building blocks. When you first get them, they're all nicely stacked in neat piles, each color in its own place. This neat and tidy setup is like a world with low entropy.
Now, suppose you shake the box really, really well. What happens? All the blocks get mixed up, right? They're scattered everywhere, and it's kind of a mess. This messiness is what we call hig ...
Como vemos, este agente nos permite explicar los procesos de forma sencilla. Perfecto, ya tenemos los diferentes agentes de nuestra estructura multi agente. Ahora vamos a crear dicha estructura. En la realidad, hay muchas formas de abordar este enfoque. Sin embargo, una de las formas que me parece más sencilla es tratar a cada uno de los agentes como una herramienta. De esta forma, será otro LLM el que use estos agentes para poder conseguir su objetivo. Esta forma de enfocarlo se llama supervisor as tools.
Así pues, vamos a crear nuestro agente:
graph = StateGraph(MessagesState)
def explainer(concept:str) -> str:
"""Explains a concept in a simple way using examples, stories and allegories.
Args:
concept: concept to explain.
Returns:
str: explanation of the concept.
"""
resp = explainer_agent.invoke({"messages": [HumanMessage(concept)]})
return resp['messages'][-1]
def researcher(query:str) -> str:
"""Searches the internet to answer your questions.
Args:
query: query to search for.
Returns:
str: best answer to the query.
"""
resp = researcher_agent.invoke({"messages": [HumanMessage(query)]})
return resp['messages'][-1]
# Bind the agents to the model
tools = [researcher, explainer]
model = ChatOpenAI(model="gpt-4o")
model_with_tools = model.bind_tools(tools)
# Define the supervisor
def supervisor(state):
msg_content = ("You are a helpful assistant, "
"you use the tools at your disposal to provide the best answer."
" You should always search on the internet before answering, "
"and explain the answer in a very simple way using examples, "
"stories and allegories."
)
message = [SystemMessage(content=msg_content)] + state['messages']
return {"messages": model_with_tools.invoke(message)}
# Create the graph
graph = StateGraph(MessagesState)
graph.add_node("supervisor", supervisor)
graph.add_node("tools", ToolNode(tools))
graph.add_edge(START, "supervisor")
graph.add_edge("tools", "supervisor")
graph.add_conditional_edges("supervisor", tools_condition)
agent = graph.compile()
_ = (
agent
.get_graph()
.draw_mermaid_png(output_file_path='imgs/researcher_explainer_graph.png')
)
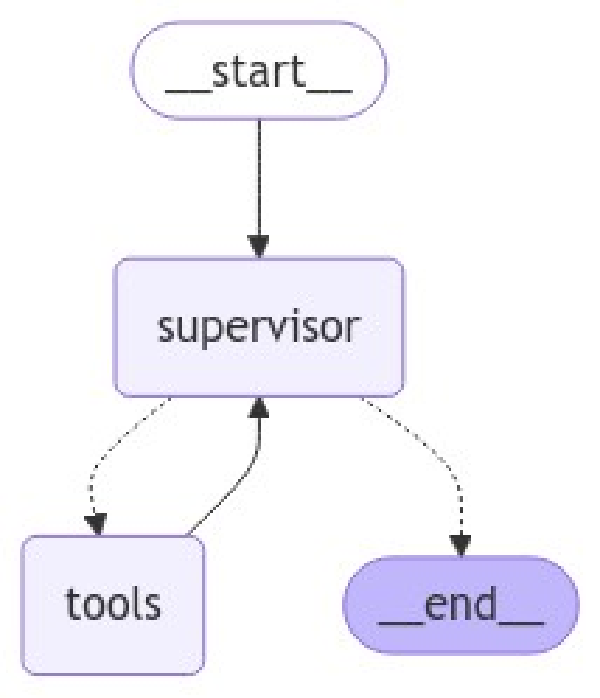
Si recuerdas, esta forma de organizar el código es lo mismo que hemos hecho al definir el agente que hacía operaciones matemáticas. Ahora, veamos a ver qué tal funciona:
msg_content = "Which where the causes of the decline of the Roman Empire?"
state = {"messages": [HumanMessage(msg_content)]}
resp = agent.invoke(state)
for message in resp['messages']:
message.pretty_print()
================================[1m Human Message [0m=================================
Which where the causes of the decline of the Roman Empire?
==================================[1m Ai Message [0m==================================
Tool Calls:
researcher (call_zcyAjHr0nzle3ivnqkT9Mjwc)
Call ID: call_zcyAjHr0nzle3ivnqkT9Mjwc
Args:
query: causes of the decline of the Roman Empire
explainer (call_xtZVtQdcCnH4DXujlquai97H)
Call ID: call_xtZVtQdcCnH4DXujlquai97H
Args:
concept: decline of the Roman Empire
=================================[1m Tool Message [0m=================================
Name: researcher
content="The decline of the Roman Empire was a complex process influenced by a variety of factors, both internal and external. Here are some of the key causes:\n\n1. **Political Instability**: The Roman Empire experienced frequent changes in leadership, civil wars, and political corruption. The constant power struggles weakened the central authority.\n\n2. **Economic Problems**: The empire faced severe financial difficulties due to overspending on wars, inflation, heavy taxation, and reliance on slave labor, which stifled innovation and economic growth.\n\n3. **Military Issues**: The Roman military became overextended and was often unable to defend the vast borders of the empire. Additionally, the reliance on mercenaries, who were often less loyal, weakened military effectiveness.\n\n4. **Barbarian Invasions**: The empire faced numerous invasions by various barbarian groups, including the Visigoths, Vandals, and Huns. The sack of Rome by the Visigoths in 410 AD was a significant blow.\n\n5. **Overreliance on Slave Labor**: The economy's dependence on slaves led to a lack of technological advancement and innovation, which was necessary for economic sustainability.\n\n6. **Weakening of the Roman Legions**: Recruitment problems and a lack of discipline in the once-powerful Roman legions undermined military strength.\n\n7. **Division of the Empire**: The division of the Roman Empire into the Western and Eastern Roman Empires (Byzantine Empire) in 285 AD by Emperor Diocletian made it difficult to govern and defend the empire effectively.\n\n8. **Cultural and Social Decay**: Some historians argue that moral decay and a loss of civic pride contributed to the decline. The traditional Roman values and civic duty eroded over time.\n\n9. **Rise of Christianity**: The rise of Christianity and the shift of focus from traditional Roman religious practices to a new, monotheistic faith may have affected the unity and cultural identity of the empire.\n\n10. **Environmental and Public Health Issues**: Some theories suggest that plagues, climate change, and other environmental factors may have contributed to the decline by reducing the population and agricultural productivity.\n\nThese factors interacted in complex ways, leading to the gradual decline and eventual fall of the Western Roman Empire in 476 AD, while the Eastern Roman Empire, known as the Byzantine Empire, continued for several more centuries." additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 483, 'prompt_tokens': 108, 'total_tokens': 591, 'completion_tokens_details': {'reasoning_tokens': 0}, 'prompt_tokens_details': {'cached_tokens': 0}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_159d8341cc', 'finish_reason': 'stop', 'logprobs': None} id='run-576720a4-c806-4d95-81ec-cf920736212e-0' usage_metadata={'input_tokens': 108, 'output_tokens': 483, 'total_tokens': 591}
=================================[1m Tool Message [0m=================================
Name: explainer
content="Alright, imagine the Roman Empire as a giant, strong tree. For a long time, this tree had strong roots and beautiful branches that reached far and wide. But over time, a few things started happening that made the tree weak and eventually led to its decline.\n\n1. **Too Big to Handle**: Imagine if you had a toy that kept growing and growing until it was too big for your room! That's kind of what happened with the Roman Empire. It got so big that it was hard to keep everything running smoothly. There were too many places to take care of, so it became difficult to manage.\n\n2. **Trouble at the Borders**: Think of this like having a big garden. If you have a fence around it, you have to make sure it's strong to keep things safe inside. The Roman Empire's borders were like that fence, but they were so long that it was hard to protect them all. People from outside, like the Visigoths and Vandals, started coming in, and the Romans couldn't stop them.\n\n3. **Leaders and Decisions**: Sometimes, if you have a team playing a game, but the captain isn't making good decisions, the team might not do well. The Roman Empire had some leaders who weren’t making the best choices, which made things even harder.\n\n4. **Money Problems**: Imagine if you had a piggy bank but kept spending more than you saved. The Romans had similar issues. They spent a lot of money, but they weren't bringing in enough, which caused trouble for the economy.\n\n5. **Changing Times**: Over time, people in the empire started to want different things. The old ways didn't work as well anymore. It was a bit like trying to play an old video game on a new computer—it just doesn't fit quite right.\n\n6. **The Empire Splits**: At one point, the Roman Empire was divided into two parts: the Western Empire and the Eastern Empire. It was like splitting that big tree into two smaller trees. The Eastern part, known as the Byzantine Empire, lasted longer, but the Western part started to fall apart.\n\nSo, just like how a tree can get weak if it’s too big, if bugs attack it, or if it doesn’t get enough care, the Roman Empire faced many challenges that made it decline. It didn’t happen overnight, but slowly, over many years." additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 486, 'prompt_tokens': 76, 'total_tokens': 562, 'completion_tokens_details': {'reasoning_tokens': 0}, 'prompt_tokens_details': {'cached_tokens': 0}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_159d8341cc', 'finish_reason': 'stop', 'logprobs': None} id='run-04693157-bfe4-4bb9-bb7d-5b86595db5bf-0' usage_metadata={'input_tokens': 76, 'output_tokens': 486, 'total_tokens': 562}
==================================[1m Ai Message [0m==================================
The decline of the Roman Empire was like a giant, strong tree that faced several challenges over time, leading to its eventual fall. Here’s a simple breakdown of the main causes:
1. **Too Big to Handle**: The Roman Empire grew so large that it became difficult to manage all its territories effectively, much like a toy that outgrows your room.
2. **Trouble at the Borders**: The empire's borders were vast and hard to defend, allowing various groups like the Visigoths and Vandals to invade, similar to having a long garden fence that’s tough to maintain.
3. **Leaders and Decisions**: Poor leadership and decisions weakened the empire, akin to a sports team with a captain who makes bad choices, leading to poor performance.
4. **Money Problems**: The empire faced economic difficulties due to overspending and not generating enough revenue, like having a piggy bank that you keep draining without saving.
5. **Changing Times**: The traditional ways of the empire didn’t fit well with changing societal needs and values, similar to trying to play an old video game on a new computer.
6. **The Empire Splits**: The Roman Empire was divided into the Western and Eastern Empires. While the Eastern part (the Byzantine Empire) lasted longer, the Western part began to crumble.
These factors, among others like political instability, military issues, and social changes, combined in complex ways, leading to the gradual decline of the Roman Empire. It didn’t happen overnight but was a slow process over many years.
Resumen y conclusión de sistema de agente con LangGraph
Espero que este extenso post te haya servido para introducirte, de forma práctica, en el mundo de los agentes. En mi opinión, los sistemas basados en agentes son una grandísima forma de poder llegar a solucionar problemas complejos a los que, actualmente, los LLMs no llegan. Sin duda alguna, creo que es una de las ramas que más evolucionará en el corto plazo (quizás incluso para cuando leas estas líneas alguna parte del post haya quedado obsoleta).
Si has encontrado el post queriendo aprender sobre sistemas basados en agentes, espero que esta guía te haya servido. En el momento de escribirla, no es un tema que esté muy documentado, por lo que me ha llevado mucho tiempo de aprendizaje y prueba y error poder escribirla. Si al menos consigue aclararte dudas o ayudar, habrá merecido la pena.
Asimismo, si quieres seguir aprendiendo sobre cómo los LLMs pueden ayudarte, te dejo este post en el que te enseño a crear un sistema RAG de Q&A usando LangChain. Dicho esto, nos vemos en el siguiente!