Introducción a Pytorch
¿Qué es Pytorch?
Pytorch es uno los frameworks para creación de redes neuronales más utilizados de hoy en día. De hecho, tal como se indica en el blog de Assembly (enlace), desde su lanzamiento en Septiembre de 2016, Pytorhc ha pasado de ser utilizado únicamente en el 7% de los papers ha ser utilizado en el 80% de los papers en 2020.
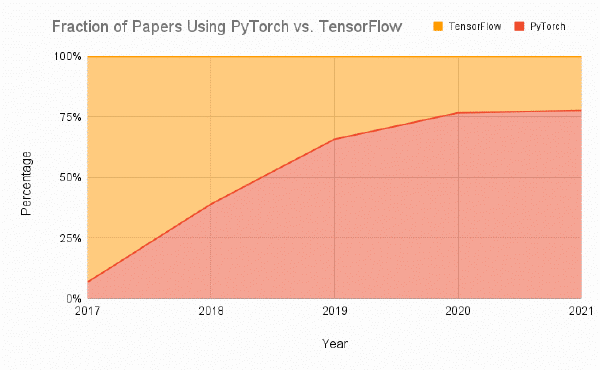
De hecho, si analizamos los modelos subidos a Huggingface, uno de los repositorios de modelos más famosos de hoy en día, también veremos como el 92% de los modelos subidos a Huggingface están desarrollados únicamente en Pytorch.
Como ves, Pytorch es una herramienta fundamental hoy en día para cualquier Data Scientists. Además, el pasado 15 de Marzo de 2023, Pytorch publicó su versión 2.
Así pues, en este tutorial de Pytorch te voy a explicar, paso a paso, cómo funciona Pytorch en su versión 2, para que así puedas añadirlo a tu kit de herramientas. ¿Te suena interesante? ¡Empecemos con el tutorial de Pytorch?
Nota: este tutorial supone que ya sabes qué es una red neuronal y cómo funciona. Si desconoces el funcionamiento interno de una red neuronal, te recomiendo que leas este post.
¿Por qué usar Pytorch?
Pytorch es una librería que te permite crear redes neuronales que corran tanto sobre CPU como GPU de forma sencilla y flexible. Esto es algo que también puedes crear con otros frameworks, como Tensofrlow. Sin embargo, si comparamos Tensorflow y Pytorch, veremos que mucha gente elige Pytorch por las siguientes razones:
- La facilidad de uso. En mi opinión, esto se da en dos sentidos:
- La forma de crear las redes neuronales y la lógica dentro de las redes es mucho más Pythonic (parecida a Python) en Pytorch que en Tensorflow.
- La propia API es mucho más intuitiva en Pytorch que en Tensorflow. (Quizás no tanto si usamos Keras, pero sí comparando con Tensforlow).
- Pytorch es mucho más fácil de debuggear que Tensorflow. La razón es que Pytorch el grafo computacional de Pytorch es dinámico, por lo que puede ir cambiando, mientras que, en Tensorflow es estático. Esto, unido al hecho de que Pytorch sea más pytchonic hace que sea mucho más facil de debuggear.
- Pytorch es mucho más usado, hoy en día, que Tensorflow. La realidad es que, en los últimos años, Pytorch ha ganado mucha popularidad. De hecho como comentába al principio del post, Pytorch es el principal lenguaje, tanto en papers, como en librerías como Huggingface.
Así pues, creo que no hay duda de que Pytorch es una herramienta fundamental para todo Data Scientist en el campo del Deep Learning. En este tutorial vamos a ver, al detalle, cómo usarla, pero para ello primero vamos a dedicar un apartado a instalar Pytorch 2 y a aprender su funcionamiento básico.t
Tutorial Pytorch: primeros pasos en Pytorch
Cómo instalar Pytorch 2
Vamos a empezar nuestro tutorial de Pytorch con lo básico: la instalación. Según indica la documentación, la principal cuestión es saber si queremos ejecutar Pytorch sobre GPU o sobre CPU.
En este sentido, existen las siguientes formas de instalar Pythorch:
- Instalación para ejecutar sobre GPU: en este caso, dependerá de la versión de CUDA que tengas. Sí, Pytorch, al igual que Tensorflow, generalmente se utiliza con gráficas de Nvidia. Aunque Pytorch también puede ser usado con gráficas de AMD (enlace), no es muy común y, por ello, no lo he incluido en este post (gracias a Antonio Aparicio por la observación).
Puedes comprobar la versión de CUDA con el siguiente comando:
!nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Wed_Sep_21_10:41:10_Pacific_Daylight_Time_2022
Cuda compilation tools, release 11.8, V11.8.89
Build cuda_11.8.r11.8/compiler.31833905_0
Como ves, en mi caso aparece que tengo la versión 11.8, por lo que tendré que instalar la versión específica para este caso:
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cu118
Si, por el contrario cuentas con la versión 11.7, el comando a ejecutar para la instalación será el siguiente:
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cu117
Instalación para ejecutar sobre CPU: hablando de redes neuronales no es lo más recomendado, ya que el uso de GPUs hace los cálculos hasta 50 veces más rápido (enlace). En cualquier caso, puedes instalar Pytorch 2 para ejecutar sobre CPU con el siguiente comando:
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cpu
Perfecto, ahora que ya tenemos Pytorch instalado estamos listos para seguir con el tutorial de Pytorch y ver cómo funciona la base de Pytorch: los Tensores.
Los Tensores en Pytorch
Un Tensor es una estructura de datos parecido a un array de Numpy, con la principal diferencia de que un Tensor puede hacer operaciones utilizando la GPU.
Así pues, vamos a utilizar los Tensores tanto para codificar los inputs de nuestra red, las capas internas de la red y sus parámetros y la capa de salida.
Cómo crear un Tensor
Existen diferentes formas de crear un Tensor. Por ejemplo, podemos crear un Tensofr de forma manual, como a continuación:
import torch
data = [1,2]
t1 = torch.tensor(data)
data = [[1,2], [3, 4]]
t2 = torch.tensor(data)
t1, t2
(tensor([1, 2]),
tensor([[1, 2],
[3, 4]]))
Como puedes ver, un Tensor no cambia mucho respecto a un Numpy array. De hecho, otra de las formas de crear un Tensor es, precisamente, dese un Numpy array:
import numpy as np
data = np.random.rand(4,2)
torch.from_numpy(data)
tensor([[0.9201, 0.1715],
[0.0026, 0.4807],
[0.0855, 0.6435],
[0.6326, 0.0596]], dtype=torch.float64)
Por último, la tercera forma de crear un Tensor, y la más común, suele ser mediante datos aleatorios. Para ello podemos utilizar el método rand de Pytorch, el cual permite crear un Tensor de unas dimensiones dadas con datos aleatorios entre 0 y 1.
Aunque puedes encontrar aquí su documentación en detalle, veamos un ejemplo de cómo funciona:
torch.rand(2,4)
tensor([[0.6680, 0.5241, 0.0054, 0.4859],
[0.0625, 0.0898, 0.2494, 0.2927]])
Perfecto, ya sabemos qué es un Tensor y cómo podemos crearlo. La siguiente preungta es, ¿qué podemos hacer con los Tensores? Veamoslo.
Operando con Tensores en Pytorch
En esta sección vamos a adentrarnos en las diferentes operaciones, métodos y funciones que solemos aplicar sobre un Tensor.
Entre ellos, una de los métodos más usados de los sensores es size, el cual permite conocer las dimensiones de un Tensor. Suele ser muy interesante para debuggear, ya que te permite tener una visión más clara de los elementos de la red.
t3 = torch.rand(2, 5)
t3.size()
torch.Size([2, 5])
Otro de los aspectos interesantes, también, es acceder a los datos internos de un Tensor, por ejemplo, los primeros 2 valores, lo conocido como *slicing*. Su funcionamiento es similar a Numpy: simplemente hay que indicar qué valor o valores quedemos para cada dimensión.
Si se definen tres valores (z, n, m) , Torch creará z Tensores de tamaño nxm. Esto mismo deberemos seguir de cara a hacer el slice de los Tensores:
t4 = torch.rand(3, 2, 2)
print(f"""
Original Tensor
{'='*40}
{t4}
\n
Slice all values of the first dimensionr (channel 1)
{'='*40}
{t4[0, :, :]}
\n
Slice all elements with position 0,0 of all dimensionns or channels
{'='*40}
{t4[:, 0, 0]}
""")
Original Tensor
========================================
tensor([[[0.7534, 0.0201],
[0.9291, 0.9882]],
[[0.8566, 0.2616],
[0.8901, 0.3453]],
[[0.5528, 0.6778],
[0.2593, 0.6801]]])
Slice all values of the first dimensionr (channel 1)
========================================
tensor([[0.7534, 0.0201],
[0.9291, 0.9882]])
Slice all elements with position 0,0 of all dimensionns or channels
========================================
tensor([0.7534, 0.8566, 0.5528])
Asimismo, también podemos aplicar operaciones matemáticas sobre las funciones, tales como la suma, la resta o la multiplicación. Muchas de estas operaciones se harán element-wise:
t1 = torch.tensor([1, 2, 3])
t2 = torch.tensor([4, 5, 6])
print(f"Sum: {t1 + t2}")
print(f"Substraction: {t1 - t2}")
print(f"Multiplication {t1 * t2}")
Sum: tensor([5, 7, 9])
Substraction: tensor([-3, -3, -3])
Multiplication tensor([ 4, 10, 18])
Además, también se pueden obtener cáculos de un Tensor, como la media. Esto puede hacerse sobre un Tensor en general, o sobre una dimensiones o dimensiones específicas. Puedes encontrar toda la documentación sobre la media aquí
t1 = torch.tensor([[1,2,3], [4,5,6], [7,8,9]])
print("General Mean")
torch.mean(t1, dtype = torch.float)
print("Mean by Dimensions")
torch.mean(t1, dim = 1, dtype = torch.float)
General Mean
Mean by Dimensions
tensor([2., 5., 8.])
Por último, vamos a ver la última operación relevante respecto a los Tensores: modificar las dimensiones de un Tensor. Para ello, contamos con dos funciones: view y reshape.
Ambas funciones sirven para modificar las dimensiones de un Tensor, aunque tienen ciertas diferencias entre ellas:
viewdevolverá los mismos datos del Tensor original, mientras quereshapepuede devolver o unviewo una copia.reshapefunciona sobre tensores contiguous y non-contiguous, mientras queviewúnicamente funciona sobre tensores contiguous.
Si quieres profundizar en las diferencias, te dejo este enlace. Por lo que a este tutorial respecta, veámos cómo funcionan estas funciones:
t1 = torch.tensor([[1,2,3,4], [5,6,7,8]])
print("Original Tensor")
print(t1)
print("Reshape to a shape of 4x2")
t1 = t1.reshape(4,2)
print(t1)
Original Tensor
tensor([[1, 2, 3, 4],
[5, 6, 7, 8]])
Reshape to a shape of 4x2
tensor([[1, 2],
[3, 4],
[5, 6],
[7, 8]])
Como veis, podemos modificar sin problema la forma del Tensor. Con esto, acabamos la visión general de los Tensores y sus principales operaciones. Ahora sí, podemos continuar con nuestro tutorial de Pytorch, creando nuestra primera red neuronal. ¡Vamos con ello!
Redes Neuronales en Pytorch
Entendiendo cómo crear redes neuronales
Como este es un tutorial de Pytorch básico, vamos a empezar por lo sencillo: una red neuronal fully connected. Más adelante veremos casos más complejos, como redes convolucionales o autoencoders.
Como ya sabes, las redes neuronales están compuestas por capas, que realizan operaciones con los datos. Pues bien, en Pytorch, cada una de las capas y operaciones que se hacen con las redes es un módulo de Pytorch diferente. Así pues, una red neuronal es un módulo de Python que cuenta, a su vez, con diferentes submódulos (diferentes capas), de una forma anidada. .
Esto puede sonar muy complejo, y lo sería si no fuera por el módulo torch.nn. El módulo nn.Module cuenta con todos los bloques que necesitas para construir tu red neuronal y te permite realizar todas las operaciones para obtener un valor de salida.
Así pues, para construir una red neuronal habrá que crear un módulo que herede la clase nn.Module y utilice sus funciones y subclases. Además, dicha clase tendrá que tener un método forward, que será el que permitirá realizar el cálculo para la obtención de un valor de salida.
Aunque puedes encontrar todos los elementos de torch.nn aquí, a continuación te listo las subclases más utilizadas:
nn.Module: esta es la clase base para todos los módulos de redes neuronales en PyTorch. Puede definir su propia red neuronal subclasificando Módulo e implementando el método forward().nn.Linear: esta clase implementa una transformación lineal de los datos de entrada. Toma el tamaño de entrada y el tamaño de salida como parámetros y calcula la salida como una matriz de multiplicación de la entrada y una matriz de peso aprendible, seguida de un término de sesgo opcional.nn.Conv2d: esta clase implementa una capa convolucional 2D, que se usa comúnmente en tareas de visión por computadora. Toma el tamaño de entrada, el tamaño de salida, el tamaño del núcleo, la zancada, el relleno y la dilatación como parámetros y calcula la salida convolucionando la entrada con un núcleo aprendible.nn.ReLU: esta clase implementa la función de activación de la unidad lineal rectificada, que se usa comúnmente en las redes neuronales para introducir la no linealidad.
Ahora que ya conocemos los ingredientes principales de cómo crear una red neuronal en Pytorch, ¡vamos a crear nuestra primera red neuronal en Pytorch!
Creando nuestra primera red neuronal en Pytorch
Vamos a crear una red neuronal multicapa muy sencilla, con una capa oculta de 16×5. Esta capa la usaremos más adelante para clasificar el dataset iris, por lo que tendrá que tener 3 valores de salida (uno por cada clase).
En Pytorch, las redes fully connected se suelen abreviar como
fc.
Así pues, con esta información y lo que hemos visto anteriormente, vamos a crear nuestra primera red neuronal en Pytorch:
from torch import nn
class Net(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(4, 16)
self.fc2 = nn.Linear(16, 5)
self.fc3 = nn.Linear(5, 3)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
Como ves, definir la red como tal no ha sido complicado: por un lado se definen las capas que componen la red y, a la hora de definir el forward, definimos las operaciones ha realizar.
De momento nuestra red está vacía y no está entrenada. Para ello, lo primero que necesitamos es contar con unos datos con los que entrenar la red. Veamos cómo cargarlos.
Cargar datos tabulares en Pytorch
Nuesta primera red neuronal en Pytorch es una red basada en datos tabulares. En general, estos son los datos más fáciles de cargar. Para ello, vamos a:
- Leer nuestros datos, usando nuestro framework favorito: Pandas, Polars, etc.
- Dividir los datos entre train y test. Para ello, usaremos la función
train_test_splitde Scikit-Learn. - Convertir los datos de train y test en tensores.
- (Opcional) Crear los Pytorch Datasets y DataLoaders. Este paso no es obligatorio si tus datos caben en memoria. En caso contrario, deberás implementarlos, tal como veremos a la hora de crear una red neuronal convolucional.
Si no conoces el funcionamiento de Scikit-Learn, te recomiendo que leas este tutorial donde lo explico paso a paso.
Así pues, vamos a cargar los datos del dataset Iris usando la función load_iris de Scikit-Learn y vamos a ver cómo convertir nuestros datos tabulares en el formato que Pytorch necesita:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import torch
from torch.utils.data import DataLoader, TensorDataset
# 1. Load Irist Dataset
iris = load_iris()
# 2. Split the dataset into training and test sets
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2)
# 3.Convert the data into PyTorch tensors
X_train = torch.tensor(X_train, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.long)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_test = torch.tensor(y_test, dtype=torch.long)
# 4. (Optional) Create PyTorch datasets and dataloaders
# train_set = TensorDataset(X_train, y_train)
# train_loader = DataLoader(train_set, batch_size=32, shuffle=True)
# test_set = TensorDataset(X_test, y_test)
# test_loader = DataLoader(test_set, batch_size=32, shuffle=False)
Ya tenemos nuestros datos de entrenamiento y test cargados. Ahora, veamos cómo entrenar nuestra primera red neuronal en Python.
Cómo entrenar tu primera red neuronal en Pytorch
Cuando entrenamos una red neuronal, generalmente necesitamos dos ingredientes:
- Una función de coste que nos sirva para calcular el error del modelo. En este sentido, el módulo
torch.nncuenta con diferentes clases para calcular errores, siendo las más conocidasnn.CrossEntropyLoss(para clasificación) ynn.MSELosspara regresión. De todos modos, puedes encontrar todas las opciones posibles aquí. - Un optimizador que nos permita optimizar los parámetros de los modelos a la hora de aplicar el back-propagation de la capa de salida a las capas ocultas. Para ello, Pytorch cuenta con el módulo
torch.optim, el cual engloba diferentes funciones de optimización, siendo los más usadosAdamySGD. Puedes encontrar todos los algortimos aquí.
Dicho esto, para entrenar nuestra red neuronal con Pytorch, tenemos que seguir los siguientes pasos:
- Iniciar la red, el optimizador y la función de coste. La convención es llamar
criteriona la función de coste,optimal optimizador yneta la red.. - Fijar los gradientes a cero aplicando el método
.zero_grad(). De esta forma nos aseguramos de que los gradientes son cero antes de calcular nuevos gradientes y así evitar que estos se acumulen. Esto es debido a que, por defecto, Pytorch guarda el buffer de los gradientes internamente. - Obtener la predicción de la red, pasando los inputs a nuestra red.
- Calcular el error generado por la red. Lo podemos hacer con el siguiente código:
criterion(outputs, labels). - Propagar el error por el resto de la red, lo cual se consigue aplicando el método
backward()de nuestra función de coste. - Aplicar el optimizador para ajustar los parámetros de la red teniendo en cuenta el error que han cometido. Este paso se logra aplicando el método
step()de nuestro optimizador. - Repetir los pasos del 2 al 6 tantas veces como queramos, ya que dichos pasos suponen una iteración.
Ahora que saber cuál es el proceso, veamos cómo hacerlo:
import torch.nn as nn
import torch.optim as optim
# 1. Initialize the neural network, loss function, and optimizer
net = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters())
errors = []
# Train the neural network
for epoch in range(1000):
running_loss = 0.0
# 2. Zero the parameter gradients
optimizer.zero_grad()
# 3. Get the prediction
outputs = net(X_train)
# 4. Calculate the error
loss = criterion(outputs, y_train)
# 5. Propagate the error
loss.backward()
# 6. Optimize the parameters
optimizer.step()
errors.append(loss)
Con esto ya tendríamos nuestra red neuronal entrenada. Vamos a ver cómo ha sido el proceso de entrenamiento, para ver de qué error partía y a qué error ha llegado:
import matplotlib.pyplot as plt
import seaborn as sns
sns.lineplot(
x = list(range(1000)),
y = [error.item() for error in errors]
)
plt.title("Neural Net Learning Curve")
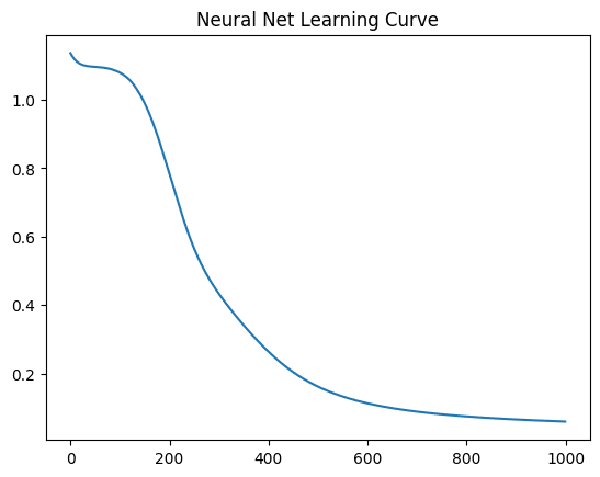
Como vemos, la red ha ido mejorando su error de entrenamiento y no ha dejado de bajar durante las 1000 primeras iteraciones. Seguramente, estemos sufriendo de overfitting, vamos a comprobarlo calculando el error de la red sobre test.
Es importante tener en cuenta que, cuando hacemos inferencia debemos poner el modelo en modo inferencia, utilizando el método eval(). Además, podemos deshabilitar el cálculo de gradientes, de tal forma que las operaciones internas no se guarden en memoria, haciendo que la ejecución sea más rápida:
# Put model in evaluation mode
net.eval()
with torch.no_grad():
# Calculate error on test
test_outputs = net(X_test)
_, predicted = torch.max(test_outputs.data, 1)
total_test = y_test.size(0)
correct_test = (predicted == y_test).sum().item()
# Calculate error on train
train_outputs = net(X_train)
_, predicted = torch.max(train_outputs.data, 1)
total_train = y_train.size(0)
correct_train = (predicted == y_train).sum().item()
print(f"Accuracy in train: {correct_train/total_train}")
print(f"Accuracy in test: {correct_test/total_test}")
Accuracy in train: 0.9833333333333333
Accuracy in test: 0.9333333333333333
Como podemos ver, en este caso el error ha sido muy bueno tanto en train como en test, seguramente porque el dataset en sí mismo no presenta una excesiva complejidad a la hora de clasificar.
Por último, vamos a guardar nuestro modelo para poder usarlo para inferencia más adelante. Para ello, es importante siempre asegurarnos de que nuestro modelo esté en modo de evaluación, aplicando el método eval(), tal como hemos visto anteriormente.
Tras ello, para guardar un modelo de Pytorch, tendreos que usar la función torch.save, tal como lo muestro a continuación:
Nota: la función
torch.saveguarda los pesos y bias usados por nuestra red neuronal, no la red neuronal en sí.
# Ensure evaluation mode
net.eval()
# specify the file path where you want to save the model
model_file = 'models/my_first_model.pt'
# save the model to the file path
torch.save(net.state_dict(), model_file)
Tras haber guardado el modelo, podríamos cargarlo para aplicar los pesos y bias sobre un modelo limpio. Para hacer dicha carga, podemos usar la función torch.load. A continuación muestro un ejemplo:
model_state_dict = torch.load(model_file)
new_model = Net()
new_model.load_state_dict(model_state_dict)
<All keys matched successfully>
Con esto ya tendríamos nuestra primera red neuronal en Pytorch. Sencillo, ¿verdad?
Ahora, sigamos con nuestro tutorial de Pytorch, viendo cómo crear redes algo más complejas, como las redes convolucionales y, por último, cómo finalizaremos el tutorial de Pytorch viendo cómo podemos sacar el máximo partido a Pytorch en su nueva versión 2.
Cómo crear una red neuronal convolucional en Pytorch
Aunque a la hora de crear la red, el proceso a seguir es el mismo (cambiando las capas), una de las cuestiones más importantes a la hora de trabajar con imágenes es que no podemos cargar todas las imágenes en memoria.
Así pues, vamos a crear una red neuronal convolucional que clasifique el dataset CIFAR-10, el cual contiene imágenes de 10 clases diferentes (enlace).
Para ello haremos uso de la librería torchvision, la cual cuenta con transformaciones, modelos y datasets específicos de visión artificial.
Así pues, lo primero de todo vamos a descargar los datos y aprender a cargarlos en batch en nuestro ordenador.
Cargar imágenes en Batch
Como hemos visto previamente, si nuestros datos no caben en memoria, debemos contar con un sistema que le indique a Pytorch de dónde tiene que coger esos datos. En este proceso necesitamos dos elementos:
- Una clase
Dataset, que permite cargar los datos en pedazos y aplica la transformación necesaria. Esta clase debe contar con dos métodos: __getitem__: dado un índice, carga una observación, en nuestro caso, una imagen, aplica la transformación que sea necesaria y devuelve tanto la imagen como su label.__len__: indica el número de datos que podemo cargar.- Un
DataLoader, el cual utiliza el Dataset definido previamente y nos permite indicar el tamaño de los batch de carga o si las imágenes deben ser aleatorias o no, entre otras cosas.
Además, para simular un entorno real, en lugar de cargar las imágenes de CIFAR-10 con la funciónn ofrecida por Pytorch, vamos a cargar directamente los pngs de la carpeta, tal como se hace en un proyecto real.
Para ello, aunque podríamos crear una clase Dataset custom, utilizaremos la función datasets.ImageFolder, la cual carga imágenes de una carpeta a modo de Dataset. Además, permite realizar cierto tipo de transformaciones en la carga.
De todos modos, para que esta función funcione correctamente necesita que el contenido tenga la siguiente estructura:
root/class_1/xxx.png
root/class_1/xxy.png
root/class_1/xxz.png
root/class_2/aaa.png
root/class_2/aab.png
root/class_2/aac.png
En el ejemplo anterior, los nombres de las imágenes no importan, lo que importa son las rutas de cómo están guardadas.
Así pues, he descargado el dataset CIFAR-10 desde Kaggle (enalace) ya tengo las imágenes en mi directorio, dentro de la carpeta data y la estructura es la siguiente:
data/
├── test
│ ├── airplane
│ ├── automobile
│ ├── bird
│ ├── cat
│ ├── deer
│ ├── dog
│ ├── frog
│ ├── horse
│ ├── ship
│ └── truck
└── train
├── airplane
├── automobile
├── bird
├── cat
├── deer
├── dog
├── frog
├── horse
├── ship
└── truck
Teniendo esto en cuenta, vamos a cargar nuestros datos:
import torch
import torchvision
import torchvision.transforms as transforms
batch_size = 64
# Define image normalization
normalize = transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
# Create the dataset
train_dataset = torchvision.datasets.ImageFolder(
root='data/train',
transform=transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
normalize
])
)
test_dataset = torchvision.datasets.ImageFolder(
root='data/test',
transform=transforms.Compose([
transforms.ToTensor(),
normalize
])
)
# Create the data loaders
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=2,
)
test_loader = torch.utils.data.DataLoader(
test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=2
)
Como podemos ver, con este código no solo cargamos las imágenes para nuestra red neuronal convolucional, sino que también aplicamos técnicas de preprocesamiento de imágenes y aumento de datos.
Ahora que tenemos una forma de cargar nuestras imágenes en nuestro modelo, estamos listos para crear y entrenar nuestra primera red neuronal convolucional en Pytorch. ¡Hagámoslo!
Entrenar tu primera red neuronal convolucional en Pytorch
El resto del proceso de cara a entrenar nuestra red neuronal convolucional en Pytorch es similar al proceso que hemos seguido a la hora de entrenar una red fully-conected.
La principal diferencia reside en las capas que utilizaremos, ya que al tratarse de redes convolucionales aplicaremos pooling, convoluciones y otra serie de cómputos que no se utilizan en las redes fully-connected.
Si no sabes qué es y cómo funciona una red neuronal convolucional, te recomiendo que leas este post.
Estas funciones las encontraremos también en el módulo torch.nn. De hecho, en este enlace encontrarás las funciones de pooling que ofrece Pytorch, en este enlace encontrarás las funciones para aplicar convoluciones y, por último, en este enlace encontrarás las funciones de padding.
import torch.nn as nn
# Define the neural network architecture
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(nn.functional.relu(self.conv1(x)))
x = self.pool(nn.functional.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = nn.functional.relu(self.fc1(x))
x = nn.functional.relu(self.fc2(x))
x = self.fc3(x)
return x
Ahora que tenemos nuestra red creada, vamos a entrenarla. En este sentido, una diferencia importante entre una red neuronal sencilla y una CNN, es el uso de GPU. Y es que, si no entrenamos nuestra CNN sobre GPU, el entrenamiento tardará mucho. Pero, ¿cómo entrenamos nuestra red neuronal en Pytorch sobre GPU? Veámoslo.
Cómo entrenar una red neuronal en Pytorch sobre GPU
Para entrenar una red neuronal con GPU en Pytorch lo primero que necesitamos es comprobar que Pytorch es capaz de usar nuestra GPU. Aunque al principio de este tutorial ya hemos visto cómo comprobar qué versión de CUDA tenemos, para asegurarnos de que Pytorch puede usar la GPU la forma más sencilla es usar la función torch.cuda.is_available(). Esta función devuelve un booleano, de tal forma que sí podemos usar nuestra GPU recibiremos un True.
torch.cuda.is_available()
True
Como vemos, en mi caso cuento con una GPU para entrenar el modelo. Ahora, para asegurar que se utilice esta GPU tenemos que:
- Convertir nuestra red en CUDA, de tal forma que las operaciones se hagan en CUDA.
- Convertir los inputs en tensores CUDA.
- Convertir los labels en tensores CUDA.
A este proceso se le llama fijar el device. En los tres casos, el proceso a seguir es usar el método to('cuda') para hacer dicha conversión y asegurarnos de que las operaciones se realizan sobre GPU.
Asimismo, en caso de que queramos que la inferencia se haga sobre GPU, tendremos que aplicar este mismo proceso tanto al cargar los datos de test como al cargar los datos reales.
Con Pytorch 2 podemos fijar el device tanto de forma global como mediante un context manager. Veremos esta funcionalidad más adelante.
Así pues, teniendo esto en cuenta, vamos a entrenar nuestra red neuronal convolucional:
net = Net()
# Convert net to cuda for GPU
net = net.to('cuda')
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(10):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
# Convert to cuda for GPU usage
inputs = inputs.to('cuda')
labels = labels.to('cuda')
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 200 == 199: # print every 200 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 200))
running_loss = 0.0
[1, 200] loss: 2.305
[1, 400] loss: 2.301
[1, 600] loss: 2.297
[2, 200] loss: 2.270
[2, 400] loss: 2.212
[2, 600] loss: 2.129
[3, 200] loss: 2.008
[3, 400] loss: 1.985
[3, 600] loss: 1.958
[4, 200] loss: 1.867
[4, 400] loss: 1.849
[4, 600] loss: 1.820
[5, 200] loss: 1.764
[5, 400] loss: 1.721
[5, 600] loss: 1.714
[6, 200] loss: 1.667
[6, 400] loss: 1.669
[6, 600] loss: 1.658
[7, 200] loss: 1.638
[7, 400] loss: 1.611
[7, 600] loss: 1.599
[8, 200] loss: 1.572
[8, 400] loss: 1.576
[8, 600] loss: 1.557
[9, 200] loss: 1.540
[9, 400] loss: 1.537
[9, 600] loss: 1.541
[10, 200] loss: 1.524
[10, 400] loss: 1.501
[10, 600] loss: 1.488
Como podemos ver, el proceso de entrenamiento es exactamente igual, salvo por una pequeña diferencia, y es que además de hacer 10 epochs de entrenamiento, en cada epoch también iteramos sobre los datos que carga el DataLoader.
Por último, vamos a hacer la predicción del modelo entrenado sobre test. Para ello, tenemos que poner el modelo en modo evaluación usando el método net.eval(), tal como hemos visto anteriormente:
import matplotlib.pyplot as plt
import PIL.Image as Image
# Define the class names
class_names = test_dataset.classes
# Set model in eval mode
net.eval()
# Load the first three images from the test dataset
images = []
for i in range(3):
img_path = test_dataset.samples[i][0]
img = Image.open(img_path)
images.append(img)
# Display the images and predicted/real labels
fig, axs = plt.subplots(1, 3, figsize=(10, 10))
for i, img in enumerate(images):
# Display the image
axs[i].imshow(img)
axs[i].axis('off')
# Get the predicted label and the real label
inputs, labels = next(iter(test_loader))
inputs = inputs[i:i+1].to('cuda')
labels = labels[i:i+1].to('cuda')
outputs = net(inputs)
_, predicted = torch.max(outputs.data, 1)
predicted_label = class_names[predicted.item()]
real_label = class_names[labels.item()]
# Display the predicted and real labels
axs[i].set_title('Predicted: {}\nReal: {}'.format(predicted_label, real_label))
plt.show()

Como podemos ver, de las 3 imágenes cargadas, nuestro modelo ha acertado una de ellas. Sí, lo sé, no es el mejor del mundo, pero ese tampoco era el objetivo. El objetivo es que puedas ver cómo se entrena una red neuronal convolucional en Pytorch.
Por último, vamos a profundizar en algunos de los aspectos claves de Pytorch 2. Al fin y al cabo, esta nueva versión es la que ha motivado este tutorial de Pytorch. Así pues, vamos a terminar nuestro tutorial de Pytorch viendo qué trae de nuevo Pytorch 2 y por qué es un gran avance!
Pytorch 2 mejorando los modelos actuales de Pytorch
En mi opinión, los dos grandes motivos para adoptar Pytorch 2 es, por un lado, que es más rápido y, por otro lado, que la API es compatible con versiones anteriores, por lo que no tienes que adaptar el código (más allá de aplicar unos pequeños cambios).
Y es que, el principal cambio de Pytorch 2 es la función torch.compile(). El funcionamiento es sencillo: tras crear el modelo, aplica la función torch.compile(). Solo con esto, tendrás mejoras de velocidad tanto en entrenamiento como en inferencia.
Importante: actualmente la función
torch.compile()no funciona en Windows. El motivo es que esta función se basa en Triton, que actualmente su ejecución en Windows está bajo desarrollo.
De hecho, tal como explican en la release note, el equipo de Pytorch ha validado estas mejoras de velocidad en 163 modelos open source diferentes, y los resultados son sorprendentes: torch.compile funciona el 93% de las veces y, cuando funciona, ofrece una mejora del tiempo del 43% (los tests se hicieron sobre una NVIDIA A100).
Y no creas que los modelos sobre los que hicieron las pruebas sean modelos obsoletos, no. Estas pruebas las aplicaron sobre modelos muy actuales, como los transformers de Hugging Face (speed up del 52%) o TorchBench.
¿Cómo consigue esto? Pues la verdad, tal como yo lo entiendo (seguramente no sea al 100% certero), es que implementa acciones para eliminar los principales cuellos de botella a la hora de entrenar redes neuronales. De estas mejoras, una de ellas es aplicar la fusion de operadores, la cual modifica la ejecución de las transformaciones sobre los datos, reduciendo el tiempo que lleva pasar losd atos de CPU a GPU y, así, haciendo el funcionamiento más rápido.
Si quieres profundizar sobre esto te recomiendo este post y este post.
Asimismo, otro cambio interesante de Pytorch 2 es que permite definir el device tanto a nivel global como mediante el uso de un context manager. En mi opinión, este cambio, aunque menor, puede ayuda mucho a evitar problemas y también hace el código más limpio.
Veamos un ejemplo con estos dos principales cambios de Pytorch 2.
Definición del device con Pytorch 2
Para definir el device de forma global, Pytorch 2 incluye la función set_default_device(). Con esto, todas las operaciones que hagamos se harán sobre el device que hayamos definido (cuda o cpu). En el siguiente ejemplo se muestra el funcionamiento:
# Set the device
device = "cuda" if torch.cuda.is_available() else "cpu"
torch.set_default_device(device)
# Check layers are created using the device
layer = torch.nn.Linear(1,2)
print(f"Layer device: {layer.weight.device}")
Layer device: cuda:0
Asimismo, también contamos con el context manager torch.device() para crear las capas y hacer las ejecuciones sobre un device específico. Veamos el ejemplo:
print("Use cuda context manager")
with torch.device('cuda'):
# Check layers are created using the device
layer = torch.nn.Linear(1,2)
print(f"Layer device: {layer.weight.device}")
print("Use cpu context manager")
with torch.device('cpu'):
# Check layers are created using the device
layer = torch.nn.Linear(1,2)
print(f"Layer device: {layer.weight.device}")
Use cuda context manager
Layer device: cuda:0
Use cpu context manager
Layer device: cpu
Como podemos ver, cada una de las capas se ha creado en su device correspondiente. Como puedes ver, esta funcionalidad de Pytorch 2, aunque no sea muy potente, sí que es muy útil.
Ahora, veamos cómo funciona el gran cambio que implementa Pytorch 2: la función compile
Cómo acelerar el entrenamiento de modelos en Pytorch 2 con compile
Para comprobar las diferencias en el tiempo de ejecución, vamos a probar a entrenar una Resnet-101 (la más grande), por 5 epochs y con un batch size más grande al previo (256). Lo haremos dos veces: en una aplicaremos la optimización de Pytorch 2 y en otra no utilizaremos dicha optimización. De esta forma, podremos ver cómo de diferentes son las ejecuciones.
Nota: según el propio release note de Pytorch, las diferencias son mucho mayores en GPUs de servidores que en GPUs dométiscas. En mi caso, utilizo una GPU doméstica, por lo que es algo a tener en cuenta.
Así pues, lo primero de todo vamos a cargar la Resnet y a modificar su capa de salida, de tal forma que devuelva 10 clases y no 1000.
import torchvision.models as models
import torch.nn as nn
# Define the device
torch.set_default_device('cpu')
model = models.resnet101(pretrained=False)
# Modify the last fully connected layer to output 10 classes instead of 1000
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 10)
model = model.to('cuda')
import torchvision
import torchvision.transforms as transforms
batch_size = 64
# Define image normalization
normalize = transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
batch_size = 256
# Create the data loaders
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=2,
)
test_loader = torch.utils.data.DataLoader(
test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=2
)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
Ahora que tengo el modelo, voy a realizar el entrenamiento. Para ello utilizaré los data loaders que ya he creado previamente a lo largo del tutorial. Asimismo, para medir el tiempo de ejecución del entrenamiento usaré la magic function %%time de Jupyter:
%%time
for epoch in range(3):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
# Get the inputs and labels
inputs, labels = data
inputs = inputs.to('cuda')
labels = labels.to('cuda')
# Zero the parameter gradients
optimizer.zero_grad()
# Forward + backward + optimize
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# Print statistics
running_loss += loss.item()
CPU times: user 1min 22s, sys: 2.16 s, total: 1min 24s
Wall time: 2min 16s
Ahora vamos a repetir el proceso, pero aplicando la función compile():
model = models.resnet101(pretrained=False)
# Modify the last fully connected layer to output 10 classes instead of 1000
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 10)
model = model.to('cuda')
compiled_model = torch.compile(model)
%%time
for epoch in range(3):
running_loss = 0.0
for i, data in enumerate(train_lo
ader, 0):
# Get the inputs and labels
inputs, labels = data
inputs = inputs.to('cuda')
labels = labels.to('cuda')
# Zero the parameter gradients
optimizer.zero_grad()
# Forward + backward + optimize
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# Print statistics
running_loss += loss.item()
CPU times: user 1min 19s, sys: 2.02 s, total: 1min 21s
Wall time: 2min 05s
Como podemos ver, al aplicar la función compile hemos conseguido reducir el tiempo de entrenamiento un 8%, de 136 segundos a 125 segundos. Sí, quizás no es un cambio muy significativo, pero se debe tener en cuenta que, no se ha utilizado en los tipos de modelos que mejor funciona (funciona mejor en modelos basados en transformers) ni tampoco contamos con una GPU de servidor.
Conclusión del Tutorial Pytorch
Como hemos podido ver al principio del tutorial, Pytorch es uno de los frameworks de Deep Learning más utilizados hoy en día. Es fácil de usar y además tiene un lenguaje muy similar a Python, lo cual hace que su curva de aprendizaje sea más sencilla.
Además, es fácil de poder aplicar sobre GPU y la construcción de redes neuronales no es excesivamente complea (siempre y cuando conozcas las bases del funcionamiento de las redes).
En cualquier caso, espero que este tutorial de Pytorch te haya servido para introducirte en Pytorch, aprender cómo funciona a grandes rasgos y servirte para conocer las ventajas que incorpora la versión 2 de Pytorch.